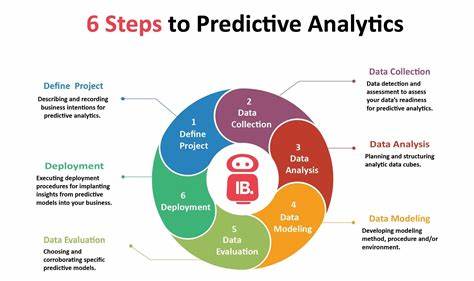
Работа с данными всегда была для меня увлекательным и многогранным процессом. Будучи специалистом, прошедшим путь от дата-журналиста до дата-аналитика и впоследствии дата-сторителлера, я вел множество проектов, связанных с извлечением информации из сырых данных и донесением её до различных заинтересованных аудиторий. Однако до недавнего времени я не имел опыта в области предиктивной аналитики, и большинство бизнес-задач, с которыми мне приходилось сталкиваться, решались с помощью описательной статистики и визуализации, а не сложных моделей машинного обучения или прогнозных алгоритмов.Моё знакомство с предиктивной аналитикой произошло в рамках подготовки к интервью на позицию старшего дата-аналитика. Мне предложили кейс, посвященный анализу оттока клиентов — одной из центральных проблем почти любой компании, работающей на потребительском рынке.
Задача заключалась в том, чтобы определить ключевые факторы, влияющие на решение клиентов прекратить взаимодействие с компанией, и на основе этих данных построить модель, которая позволила бы предсказать вероятность оттока каждого клиента.В этом проекте я впервые применил метод ассоциативных правил, также известный как анализ «market basket» или анализ товарных корзин. Обычно данный метод применяется в ритейле для выявления связей между покупками разных товаров, но в нашем случае я использовал его для обнаружения взаимосвязей между различными характеристиками и поведением клиентов. Это позволило выявить скрытые закономерности и связи, которые не всегда очевидны при традиционном анализе.Одной из самых больших сложностей стал этап подготовки и трансформации данных.
Первоначальный набор содержал множество разнородных и неполных данных, а также категориальные признаки, которые было необходимо преобразовать в формат, пригодный для анализа с помощью выбранного алгоритма. Преобразование и кодирование данных заняли значительную часть времени и потребовали детального понимания как бизнес-контекста, так и технических аспектов обработки данных.Кроме того, пришлось обратить внимание на качество данных — избавляться от пропусков, аномалий и явных ошибок. Без качественной и корректно подготовленной базы данных надежность и точность модели была бы под вопросом. После того как данные были приведены в надлежащий вид, я приступил к применению алгоритмов, проверке гипотез и интерпретации результатов.
Результаты предсказательной модели оказались весьма информативными. Они позволили не только предвидеть клиентов с высоким риском оттока, но и понять, какие именно факторы и комбинации признаков с наибольшей вероятностью приводят к потере клиента. Это дало возможность бизнес-команде выстроить проактивные стратегии удержания, направленные на группы с повышенной вероятностью ухода.Опыт работы с предиктивной аналитикой стал для меня важным шагом в карьере, расширив кругозор и профессиональный инструментарий. Он показал, что глубокое понимание данных и умение их правильно подготовить зачастую важнее использования сложных алгоритмов.
Без качественной работы на этапе подготовки данные не могут стать основой для действительно ценных и рабочих инсайтов.Далее я планирую подробно рассказать о каждом этапе проекта — от постановки задачи и сбора данных до построения модели и анализа её результатов. Хотелось бы поделиться с читателями не только теорией, но и практическими советами по работе с реальными данными, а также рассказать о самых типичных проблемах и способах их решения.В целом, этот проект стал началом моего пути в сфере предиктивной аналитики и машинного обучения и дал понять, как важно сочетать технические знания с бизнес-смыслом. Желающие углубиться в детали могут ознакомиться с полным разбором кейса, который я опубликовал на своём сайте.



![LLMs Are Bayesian, in Expectation, Not Realization [pdf]](/images/834EB8ED-43D0-4C6D-9BAF-8B8E5F430750)



