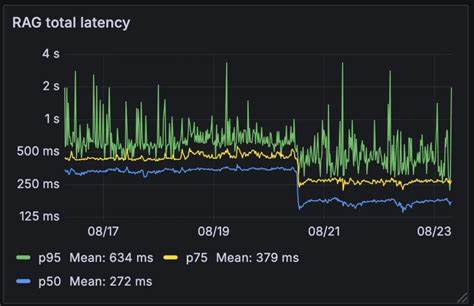
Retrieval-Augmented Generation (RAG) уже давно зарекомендовал себя как эффективная технология, повышающая точность и релевантность ответов искусственного интеллекта за счет использования больших баз знаний. Вместо передачи всей базы данных напрямую огромным языковым моделям, RAG работает с извлечением наиболее релевантной информации на основе векторных эмбеддингов. Однако внедрение этого подхода в реальных продуктах всегда сопровождается вызовами, главным из которых является латентность - задержка в обработке запросов, которая может существенно снизить качество взаимодействия с пользователем. В нашей системе мы смогли увеличить скорость работы RAG почти в два раза, сократив среднее время отклика с 326 миллисекунд до 155, что стало выдающимся достижением для таких технологий. В этом обзоре мы детально расскажем, как нам удалось оптимизировать технологический процесс, почему именно этап переписывания запросов был узким местом и как инновационный метод "гонки моделей" помог нам решить проблемы производительности и устойчивости.
Основой работы RAG является особый этап - переписывание запросов пользователя. В реальных сценариях часто встречаются ситуации, когда пользователи обращаются не с чистым, лаконичным запросом, а с вопросами, ссылающимися на предыдущие реплики в диалоге. Например, вопрос "Можно ли настраивать эти лимиты в зависимости от пиковых трафиков?" самостоятельно не несет полной информации без контекста. Чтобы сделать работу поиска более точной, систему необходимо "заготовить" полноценный и понятный запрос, развернув весь диалог, чтобы раздобытая информация точно отвечала на вопрос. В традиционных установках этот переписывающий шаг существенно замедлял работу всей цепочки.
Основной причиной тому являлась зависимость от одного внешнего языкового сервиса, который обрабатывал запросы последовательно. Из-за этого один этап мог занять до 80 процентов всего времени обработки запроса. Другим важным элементом нашей архитектуры стала интеграция RAG непосредственно в поток обработки каждого пользовательского запроса, а не только по особым случаям. Такой подход гарантирует стабильное качество и полноту данных, но повышает требования по скорости. Поэтому все задержки и узкие места внутри системы начинают влиять на конечный пользовательский опыт гораздо сильнее и требуют более продвинутых решений.
Чтобы устранить проблемные задержки, мы пересмотрели подход к переписыванию запросов и внедрили концепцию "гонки моделей". Суть этой идеи заключается в параллельной отправке одного и того же запроса на обработку нескольким языковым моделям одновременно. В нашем случае использовались как внешние провайдеры, так и собственные самообслуживаемые модели Qwen 3-4B и 3-30B-A3B. В такой схеме нам не нужно ждать ответа одной модели - достаточно получить результат первой, которая завершит вычисления и предоставит валидный ответ. Если же ответ не приходит в течение одной секунды, система автоматически переходит к использованию исходного, не переписанного запроса, что позволяет избежать "зависания" диалога и поддерживать непрерывность общения.
Такой подход изменил правила игры. Во-первых, время отклика заметно уменьшилось, потому что задержка одного медленного компонента не влияла на всю систему - выигрыш в скорости добавлялся благодаря конкуренции между моделями. Во-вторых, повысилась устойчивость работы: если один из провайдеров испытывал нагрузку или технические проблемы, другие модели продолжали обслуживать запросы без ущерба для качества. Такая вариативность и резервирование позволили обеспечить стабильную работу даже в условиях пиковых нагрузок и непредсказуемых сбоев в инфраструктуре. Результаты оптимизации впечатляют.
В среднем, время обработки запроса сокращено почти в два раза - с 326 миллисекунд до 155. Этот рост производительности ощутимо снижает накладные расходы системы и позволяет работать с RAG на каждом запросе без деградации пользовательского опыта. Более того, сокращение времени отклика сказывается положительно на общих метриках системы, таких как уровень удовлетворенности пользователей, скорость обработки массовых потоков данных и экономия вычислительных ресурсов. Стоит отметить, что многие компании применяют RAG только выборочно, когда требуется добиться максимальной точности, жертвуя при этом производительностью. Использование RAG на всех этапах диалога, как в нашей системе, ставит высокие требования к скорости.
Поэтому достижение уровня в 155 миллисекунд открывает новые возможности для масштабирования и применения RAG в реальном времени даже в крупных корпоративных решениях с обширными и постоянно обновляемыми базами знаний. Важность такой оптимизации особенно ярко проявляется в контексте разговорных AI-агентов, которые взаимодействуют с пользователями в режиме реального времени и должны быстро и корректно реагировать на запросы, в том числе сложные и многоэтапные. Быстрая обработка запросов с минимальными задержками позволяет сохранять естественность диалога и держать качество общения на высоком уровне. Кроме того, наша архитектура значительно упрощает поддержание инфраструктуры и снижает риски, связанные с зависимостью от внешних сервисов. Использование собственных моделей в сочетании с внешними позволяет гибко переключаться и поддерживать стабильную работу даже при непредвиденных обстоятельствах, например при сбоях у провайдеров LLM или пиковых нагрузках.
Такой подход демонстрирует преимущества гибридной модели построения современных AI-систем. Техническая реализация модели гонки включает не только параллельные запросы, но и интеллектуальные fallback-алгоритмы, которые выбирают наиболее подходящий для текущей ситуации вариант, минимизируя риск задержек и снижения качества. Немаловажно и то, что уже существующая инфраструктура для поддержки собственных моделей была эффективно использована без значительных дополнительных затрат, что было важным фактором экономической эффективности решения. В конечном итоге, сокращение латентности и повышение надежности делают систему более гибкой, масштабируемой и готовой к работе с постоянно растущими массивами данных и сложными сценариями взаимодействия. Наш опыт показывает, что грамотное сочетание современных языковых моделей, параллельных вычислений и систем резервирования может существенно повысить показатели работы AI-агентов и обеспечить конкурентные преимущества в быстро меняющемся мире технологий искусственного интеллекта.
Таким образом, наши инновации в области ускорения RAG не только позволили повысить производительность, но и улучшили стабильность, качество и экономическую эффективность всей системы. Эти достижения открывают новые горизонты для внедрения RAG в самые разные области от клиентской поддержки и финансовых сервисов до телекоммуникаций и технологий обучения, где важны быстрые, точные и контекстно осведомленные ответы AI-агентов. В будущем мы планируем и дальше развивать этот подход, интегрируя новые модели, оптимизируя алгоритмы и расширяя сценарии использования, чтобы создавать еще более мощные, быстрые и точные интеллектуальные системы, которые смогут отвечать на вызовы современного цифрового мира и служить надежным инструментом для бизнеса и пользователей по всему миру. .