В современном мире информационного шума и огромного объема чтения качественное управление знаниями становится все более актуальной задачей. Многие читатели и исследователи используют Readwise для того, чтобы сохранять и систематизировать свои заметки, цитаты и выделения из книг и статей. Однако при росте объема данных все более ощутимым становится вопрос быстрого и точного поиска нужной информации внутри своей библиотеки. Традиционные методы поиска по ключевым словам или тегам часто оказываются недостаточно эффективными, особенно когда речь идет о сложных запросах и контекстуальном понимании содержания. Именно здесь на помощь приходит локальный семантический поиск — технология, которая способна преобразовать вашу библиотеку Readwise в мощный инструмент для изучения, анализа и интеграции знаний.
Readwise изначально позиционируется как сервис для управления выделениями из книг и статей, а также для их организации с целью максимальной пользы для пользователя. Он предоставляет удобный интерфейс и возможность синхронизации с популярными платформами, такими как Kindle, Pocket и Instapaper. Но несмотря на всесторонний функционал, из коробки Readwise не всегда способен предложить глубину и гибкость поиска, необходимую для интеллектуальной работы с большими массивами данных. Это связано с тем, что традиционный поиск завязан на простое сопоставление введенного текста с содержимым заметок, без учета контекста и смысловых связей. Решение проблемы предлагает интеграция технологии семантического поиска, которая основывается на современных методах обработки естественного языка и машинного обучения.
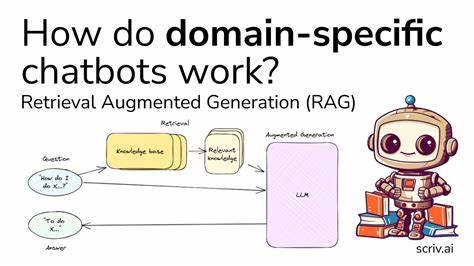
Суть подхода — не просто находить текстовое совпадение, а понимать значение запроса и документов, сравнивать смысловые векторы и предлагать релевантные результаты даже при отсутствии точного совпадения ключевых слов. Для пользователей Readwise появился проект readwise-vector-db — это инструмент, позволяющий организовать локальный семантический поиск по базе выделений и заметок, при этом сохраняя приватность данных и обеспечивая высокую скорость работы. Основой readwise-vector-db является использование PostgreSQL с расширением pgvector, которое предоставляет возможность хранения и поиска по многомерным векторам. Векторизация данных обеспечивается с помощью различных моделей машинного обучения, таких как OpenAI или альтернативных эмбеддингов. Таким образом, каждая заметка или выделение преобразуется в числовой вектор, отражающий ее смысл и контекст.
При поисковом запросе система формирует вектор запроса и ищет в базе ближайшие по смыслу совпадения, что значительно улучшает качество поиска. Одним из ключевых преимуществ решения является возможность развернуть весь стек у себя локально или на выбранном облачном провайдере, что дает полный контроль над собственными данными. Это особенно важно для тех, кто ценит конфиденциальность или работает с профессиональной информацией, не подлежащей размещению на сторонних серверах. При этом проект предусматривает поддержку как классической клиент-серверной архитектуры с Docker и локальным Postgres, так и облачных вариантов с Supabase, позволяющих быстро стартовать без технических сложностей. Ещё одно важное достоинство readwise-vector-db — оптимизация под serverless-развертывания, включая платформы Vercel.
В проекте реализована технология Server-Sent Events (SSE) для потоковой передачи результатов поиска по протоколу MCP, что обеспечивает мгновенную выдачу релевантных ответов и поддержку множества одновременных соединений. Благодаря этому пользователи могут масштабировать приложение без потери производительности и делать поиск максимально отзывчивым. Для интеграции необходимо лишь несколько команд в терминале: клонирование репозитория, установка зависимостей с помощью Poetry, запуск контейнеров Docker для базы данных и запуск API сервера. Все операции подробно описаны в документации, что делает процесс простым даже для тех, кто не обладает глубокими знаниями в DevOps. После первичной синхронизации с Readwise пользователи получают полный набор инструментов для умного поиска и фильтрации выделений по дате, источнику, тегам и другим параметрам.
Отдельно стоит выделить примеры использования API для проведения сложных семантических запросов и потокового поиска. Они открывают возможности для разработчиков создавать собственные клиентские приложения или расширения, интегрирующие поисковый движок с другими системами. Это расширяет горизонты применения решения, начиная от личного использования и заканчивая корпоративными системами управления знаниями. В итоге локальный семантический поиск в Readwise трансформирует работу с текстовой информацией. Вы перестаете вести бесполезный поиск по ключевым словам и начинаете работать с истинным смыслом и связями между заметками.
Это особенно актуально для ученых, аналитиков, разработчиков и всех, кто систематически углубляется в большие объемы профессиональной литературы или статей. Более того, проект имеет открытую архитектуру и поддерживается сообществом, что делает его перспективным и постоянно улучшаемым инструментом. Внедрение readwise-vector-db в рабочий процесс позволяет экономить время на поиск нужных цитат и идей, расширяет возможности анализа прочитанного и повышает общую продуктивность чтения. Семантический поиск помогает не только найти информацию, которую вы уже сохранили, но и выявить новые взаимосвязи, ранее остававшиеся незамеченными. Это своего рода интеллектуальный помощник, доступный каждый раз, когда вы обращаетесь к своей коллекции знаний.
Для тех, кто хочет выйти за рамки базовых функций Readwise и использовать все преимущества современной обработки текстов и искусственного интеллекта, локальный семантический поиск — незаменимый инструмент. Он делает библиотеку живой, активной базой знаний, а не просто хранилищем заметок. Это будущий стандарт работы с текстами, который уже сегодня доступен каждому, кто готов сделать следующий шаг в управлении информацией.