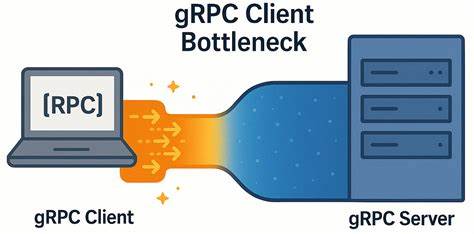
gRPC широко используется в современных распределённых системах благодаря своей высокой производительности, надёжности и удобству для межсервисного взаимодействия. Эта платформа, построенная поверх HTTP/2, позволила упростить коммуникации между микросервисами, при этом сохраняя высокую пропускную способность и низкую задержку. Однако в условиях сетей с особенно низкой задержкой неожиданно выявляется проблема, существенно влияющая на производительность клиентов gRPC, что стало предметом исследования специалистов из компании YDB, работающей с распределённой СУБД с поддержкой строгой консистентности и транзакций ACID. Несмотря на современные оптимизации, их тщательное тестирование показало наличие скрытого узкого места у клиента gRPC, ограничивающего скорость обработки запросов даже в мощных и малых кластерах. Эти наблюдения оказались крайне важными для всех, кто стремится к максимальной эффективности в высокопроизводительных сетях.
В основе протокола gRPC лежит идея использования каналов (channels), каждый из которых устанавливает собственное TCP-соединение с сервером и поддерживает несколько потоков запросов (stream), соответствующих HTTP/2 stream. Приоритетным подходом для высоконагруженных приложений является создание отдельных каналов для различных направлений нагрузки или организация пула каналов с разными параметрами, позволяющая распределять нагрузку и избегать очередей в одном соединении. В документации gRPC подчёркивается ограничение на количество одновременных потоков на соединение (обычно не более 100), что накладывает рамки на способность одного канала обрабатывать множество параллельных запросов без задержек. Однако, как показало исследование, само по себе создание множества каналов не всегда решает проблему, если параметры каналов не оптимизированы или каналы вынужденно делят один и тот же TCP-сокет. Для глубокого анализа подобной проблемы команда YDB разработала свой тестовый микробенчмарк, представляющий собой простой ping-протокол на базе gRPC, реализованный на C++ с использованием современных версий gRPC (v1.
72.0). Такой минимум логики позволил выявить именно системные ограничения и поведение внутреннего механизма gRPC без влияния нагрузки бизнес-логикой. Эксперименты проводились на мощных серверах с двумя Intel Xeon Gold 6338 (по 32 ядра каждый с гиперпотоками) с использованием сетевого соединения 50 Гбит/с и миллисекундными задержками порядка 0.04 мс, что полностью исключало сетевые узкие места.
Результаты оказались весьма неожиданными: несмотря на обилие ресурсов, при увеличении числа параллельных запросов внутри одного канала нагрузка росла далеко не линейно, а задержки возрастали практически пропорционально количеству одновременных вызовов. Даже при низком числе одновременных запросов респонсы не достигали сети доскональной скорости. Сетевой трафик прослеживал полную работоспособность соединения без признаков задержек на уровне TCP, без потерь пакетов, включённой опцией TCP_NODELAY и правильным размером окна TCP, полностью исключая типичные проблемы TCP-соединений. Анализ tcpdump и Wireshark показал, что именно клиентская часть gRPC становится бутылочным горлышком, нарушая ожидания от идеальной передачи запрос-ответ в менее чем 200 мкс. Дальнейший разбор показал, что причина лежит в реализации gRPC и том, как клиент управляет каналами и потоками.
Оказалось, что все gRPC каналы без специально заданных уникальных параметров, автоматически объединяют TCP-соединения через HTTP/2 мультиплексирование, что приводит к очередности запросов и серьезным задержкам в локальных потоках. Решающим стало использование для каждого рабочего потока клиента отдельного канала с индивидуальными параметрами конфигурации или включением опции GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL, что позволило «раздробить» нагрузку и создать собственные TCP-соединения под каждый канал. Вследствие этого средняя пропускная способность выросла в 4-6 раз, а задержки устойчиво снизились, сохраняясь на минимально допустимом уровне даже при высоком количестве параллельных запросов. Обнаруженные результаты особенно важны при работе в кластерах с ограниченным числом серверных узлов, когда ресурсы на стороне сервера не исчерпаны, но узким местом становится клиентская часть. Текущие методики балансировки и оптимизации gRPC должны учитывать этот сценарий, чтобы избежать ситуации, когда при уменьшении числа узлов наблюдается при этом рост клиентской латентности и появления простоев на сервере.
Решение заключается в грамотной конфигурации клиента, а именно в выделении каналов с уникальными аргументами и раздельных пулов соединений, что минимизирует внутренние по очереди и контови конкуренции. Интересно отметить, что в условиях сетей с высокой задержкой (например, 5 мс RTT) данный клиентский бутылочный горлышко практически терял своё значение, так как сетевые задержки доминировали и нивелировали проблему внутри gRPC клиента. Это позволяет полагать, что для облаков с расположением дата-центров на большом расстоянии данный эффект не проявляется явно, но в локальных сетях с низкой латентностью и высокоскоростными соединениями становится особенно заметен. Выводы исследования YDB демонстрируют, что при работе с gRPC в интенсивных и чувствительных к задержкам системах одной из ключевых оптимизаций должна стать правильная организация клиентских каналов. Построение уникальных каналов для каждого рабочего потока и использование локальных пулов каналов позволяют существенно повысить общую пропускную способность и сократить время отклика, что особенно важно для распределённых баз данных, микросервисов и других современных высоконагруженных приложений.
Эти практики не всегда очевидны из официальной документации, поэтому опыт профессионалов и реальные измерения имеют высокую ценность для индустрии. Для разработчиков и администраторов, занятых оптимизацией систем на основе gRPC, полезно обратить внимание на следующие моменты. При проектировании нагрузки рекомендуется избегать чрезмерного объединения каналов в один TCP-сокет, внимательно следить за параметрами каналов и использовать флаги конфигурации, которые помогают создавать независимые подканалы внутри клиента. Также важно внимательно отслеживать метрики, включая не только серверную, но и клиентскую часть, чтобы избежать узких мест на стороне обращения к API. В целом, несмотря на впечатляющие возможности gRPC, как и любая технология, она требует должной настройки и понимания внутренней архитектуры для эффективного и стабильного функционирования в любых условиях.
Результаты данного исследования расширяют представление о том, что именно является узким местом в системах с низкой задержкой и как этот вызов преодолеть. Они служат ценным руководством для всех, кто работает с высокопроизводительными распределёнными системами и желает извлечь максимум из возможностей современных коммуникационных протоколов.