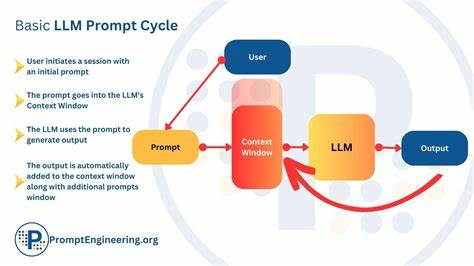
Большие языковые модели (LLM) становятся все более популярными и мощными инструментами, которые помогают решать разнообразные задачи в области обработки естественного языка. Однако при работе с длительными сессиями нередко возникают проблемы, связанные с «дрейфом памяти» — когда модель теряет контекст, повторяет себя или уходит от изначальной темы разговора. Эти недостатки снижают качество взаимодействия и ограничивают возможности LLM в более сложных сценариях. Именно с целью минимизации подобных проблем был разработан и подробно обсуждён протокол, позволяющий стабилизировать память LLM и улучшить качество диалогов в длинных сессиях, однако первоначальный пост не охватил все аспекты проблемы и решений. В данной статье подробно рассмотрим, что такое дрейф памяти, почему он возникает, как можно его снизить, и какие выводы стали возможны после анализа реальных отзывов пользователей и практического тестирования.
Дрейф памяти в больших языковых моделях в первую очередь связан с ограничениями объёма контекста, который модель может удерживать одновременно. Большинство современных LLM имеют ограничение по количеству токенов, которые они могут обрабатывать за один запрос. При длительном взаимодействии информация из ранних этапов диалога постепенно «выпадает» из активного контекста, что приводит к потере связности и нарастанию ошибок. Более того, во время продолжительной работы модель может начинать отвечать фрагментами, которые кажутся оторванными или нерелевантными, что выглядит как «дрейф» – уход от темы. Одним из ключевых источников этой проблемы является также склонность моделей к повторным срабатываниям и генерации ответов на основе случайных или некорректных интерпретаций предыдущей информации.
При этом в ходе сессий можно заметить изменение стиля, ухудшение логики и появление бессмысленных фрагментов. Это особенно заметно в долгих чатах или при использовании LLM для сложных последовательных задач, где важна сохранность намерений и точность деталей. Для решения этих задач и был разработан протокол MARM (Memory And Reseeding Management), который основывается на структурированном подходе к хранению и обновлению контекста. Центром концепции стала идея не только использовать продуманные формулировки запросов, но и вводить специальные структурные элементы, позволяющие отслеживать ход диалога и управлять памятью модели. В основе метода лежит несколько важных компонентов.
Первый — это ведение временных меток и журналов каждого взаимодействия, что позволяет моделью и управляющей системе понимать, когда и в каком порядке была получена или отправлена информация. Это помогает исключать путаницу и возвращаться к ключевым моментам, не теряя их из вида. Второй важный элемент — отслеживание намерений пользователя (intent tracking). Благодаря этому система может фиксировать, какие цели и потребности заложены в диалоге, а значит, направлять ответы более точно и последовательно. Третий — использование блоков «reseeding», которые периодически вводят обновления или перезапускают контекст, чтобы предотвратить накопление ошибок и «зашумление» информации.
Наконец, ключевое значение имеет установка строгого формата выдачи ответов, где каждый ответ структурирован и стандартизирован, что облегчает мониторинг и анализ взаимодействия. Первые результаты применения протокола показали заметное улучшение стабильности и качества диалогов. Важным источником данных для анализа послужили реальные отзывы пользователей, размещённые на таких платформах, как GitHub, Reddit и Discord. Регулярное изучение жалоб и претензий позволило выявить наиболее типичные сценарии провалов и долгоиграющие проблемы с контекстом. На этом основании были систематизированы ошибки и составлен «схематический» подход к повышению контекстной согласованности.
Оригинальная публикация и исходный код проекта доступны на GitHub, где более подробно описан протокол и механизмы его работы. В рамках обсуждения и последующих комментариев сообщества были подняты ценнейшие вопросы, касающиеся не только технической стороны, но и общих направлений развития технологий долговременной памяти у LLM. Несмотря на успешные шаги в устранении дрейфа, из опыта применения протокола стало понятно, что важной недостающей составляющей является более глубокая интеграция между структурированным трекингом и адаптивной логикой модели. Изначально разработанный подход сбалансировал хранение конткеста с фиксированными форматами, что дало эффект, но также накладывает ограничения на гибкость ответов и динамичность диалога. В будущем предстоит исследовать возможности машинного обучения для автоматического определения ключевых точек сессии и более интеллектуального подбора моментов для «reseeding».
Другим направлением развития является интеграция с внешними базами знаний и памятью вне модели, чтобы обеспечить долговременное хранение информации и её актуализацию без необходимости постоянно перегружать сам LLM. Такой гибридный подход может позволить масштабировать диалоги и сохранять память неограниченного размера при сохранении высокой точности и релевантности. Кроме того, важную роль играет пользовательский опыт и механизмы обратной связи. Практика показала, что активное и своевременное вовлечение пользователей в процесс формирования запросов и получение развернутых отзывов существенно ускоряет выявление узких мест и корректировку протокола. Сообщество, объединённое вокруг идеи улучшения памяти LLM, демонстрирует высокий потенциал для совместной разработки более совершенных и устойчивых решений.
Итогом анализа стало понимание, что борьба с дрейфом памяти требует комплексного подхода: чёткого структурирования диалогов, регулярной переадресации контекста, эффективного управления намерениями пользователя и взаимодействия с внешними ресурсами. Собранный опыт и наработки протокола MARM позволяют сделать уверенный шаг вперёд, но остаётся ещё много пространства для оптимизации и внедрения новых идей. Долгосрочные исследования в сфере улучшения памяти больших языковых моделей обещают значительные перспективы для создания более надежных и интеллектуальных систем, которые смогут поддерживать сложные, непрерывные и осмысленные диалоги с пользователями без утраты информации и качества. Совместная работа разработчиков, исследователей и пользователей поможет раскрыть полный потенциал LLM и вывести взаимодействие с искусственным интеллектом на качественно новый уровень.