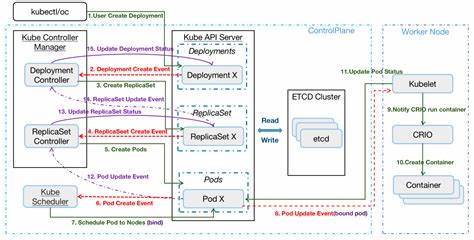
Kubernetes уже давно стал стандартным инструментом для управления контейнеризированными приложениями. Однако при расширении кластера до сотен и тысяч узлов, а также сотен тысяч подов возникают серьезные вызовы, связанные с производительностью и надежностью компонентов управления. Одним из ключевых уязвимых мест является Kubernetes List API, который при интенсивном использовании может привести к деградации работы кластера и даже к сбоям. Важно разобраться, почему происходит такое ухудшение, и какие методы позволяют его предотвратить, чтобы обеспечить стабильную работу больших Kubernetes-сред. Сердце управления Kubernetes — kube-apiserver, компонент, принимающий запросы API, управляющий состоянием кластера и взаимодействующий с системой хранения etcd.
List API — это набор методов, возвращающих списки объектов, например, список всех подов или сервисов. В небольших кластерах такие операции проходят быстро и без нагрузки. Однако в масштабах сотен тысяч объектов обычный список может превратиться в слишком большой и тяжелый запрос для kube-apiserver. Основной проблемой становится чрезмерное использование ресурсов при выполнении list-запросов. Когда API сервер обрабатывает большие коллекции, он расходует значительное количество процессорного времени для извлечения данных из etcd, а затем для сериализации и кодирования ответов (обычно в JSON или protobuf).
При этом в памяти приходится держать весь ответ сразу, что приводит к высоким пиковым нагрузкам по памяти и интенсивному сборщику мусора. Такая ситуация способствует возникновению тайм-аутов или даже завершению работы процесса с ошибками Out-Of-Memory (OOM). Для уменьшения затрат ресурсов применяют механизм пагинации, когда результат передается частями с использованием параметра limit и токена continue. Это позволяет серверу обрабатывать и передавать данные небольшими блоками, снижая нагрузку на CPU и память. Однако пагинация не всегда гарантирует уменьшение нагрузки, особенно если запросы идут с определенными параметрами, например, с resourceVersion=0, что заставляет kube-apiserver игнорировать limit и отдавать полный список за один раз.
Ключевым улучшением в Kubernetes начиная с версии 1.31 стал переход к обслуживанию большинства get и list запросов через watch cache — внутренний кэш, который отражает текущее состояние кластера в памяти API сервера. Вместо обращения напрямую к etcd, запросы обрабатываются кэшем, что значительно сокращает задержки и нагрузку на бэкенд. В сочетании с оптимизированными индексами в watch cache стало возможным быстро и эффективно выполнять фильтрацию по меткам (label selectors) и полям (field selectors) без необходимости загрузки всей коллекции из etcd. Однако до версии 1.
31 подобные запросы обрабатывались без использования watch cache, из-за чего фильтрация была крайне дорогой по ресурсам — серверу приходилось выгружать и фильтровать сотни тысяч объектов вручную. Такая нагрузка могла привести к критическим сбоям, особенно если множество клиентов одновременно отправляли запросы с фильтрами, которые не могли эффективно использоваться для сокращения объема данных. Совместное использование пагинации и watch cache до сих пор имеет ограничения. Запросы вида limit=500 и resourceVersion=0 приводят к тому, что аписервер игнорирует параметр лимита и возвращает полный список, что снова создает критическую нагрузку по памяти и CPU. Эта «смертельная комбинация» в некоторых случаях способствовала масштабным сбоям в крупных кластерах, порождая длительные рестарты и деградацию.
В будущих релизах Kubernetes ожидаются улучшения, которые позволят кэшу поддерживать пагинацию и ограничивать объем возвращаемых данных, тем самым снижая нагрузку на систему. Еще одной важной проблемой является высокая конкуренция между одновременными list-запросами. Отдельно один такой вызов может не нанести ущерба, но если их сотни и тысячи одновременно, например, при запуске большого количества агентов или контроллеров, нагрузка на kube-apiserver резко возрастает, что чревато резким увеличением потребления памяти и CPU. Без специальных ограничений и механизмов управления очередями нагрузка может стать неконтролируемой. API Priority and Fairness (APF) — инструмент, предназначенный для регулирования приоритетов запросов, пока не учитывает стоимость в памяти подобных тяжелых list-запросов должным образом.
Это означает, что громоздкие запросы могут незамедлительно вызвать проблемы, несмотря на настройки. Рекомендуется тщательно контролировать вызовы в кластере, используя системные аудиты и мониторинг, выявляя и предотвращая неэффективные и ресурсоемкие list-запросы. Роль контроллеров и клиентов в эксплуатации API крайне велика. Многие используют стандартные informer-паттерны, которые базируются на листинге и watch событий. Клиенты, которые не применяют пагинацию или используют неэффективные параметры, создают нездоровую конкуренцию за ресурсы.
Отдельно стоит избегать использования daemonset'ов и агентов на каждом узле, которые делают свои собственные list-запросы к API серверу для получения локальной информации. Лучше полагаться на локальный kubelet API для таких задач, что значительно снижает нагрузку на кластер. В свежих версиях Kubernetes с выпуском 1.33 введены механизмы снижения потребления памяти при кодировании ответов. Специальные оптимизации позволяют строить JSON-ответы по частям, а не формировать весь объект целиком перед отправкой.
Это уменьшает пиковые затраты памяти и уменьшает нагрузку на сборщик мусора, улучшая стабильность при работе с большими списками. Технология WatchList, которая должна была распространить возможности watch на потоковую отправку существующих объектов без первоначального массового лист-запроса, планируется к внедрению и стабилизации в ближайших версиях. Такая реализация позволит упростить старт контроллеров и сделать систему значительно более экономной по ресурсам за счет уменьшения объема оперативной памяти для буферизации объектов. Для оптимальной производительности рекомендуется использовать не менее версии Kubernetes 1.31 с обновленным etcd (версии 3.
4.31+ или 3.5.13+), чтобы обеспечить использование watch cache и фильтрации в памяти. Также рекомендуется внедрять мониторинг и аудит API вызовов, чтобы своевременно обнаруживать и корректировать неблагоприятные паттерны запросов.
Важно настроить правильные RBAC политики, ограничивая права доступа к list API, особенно при работе с крупными и чувствительными к нагрузке кластерными системами. Правильное распределение приоритетов запросов и ограничение на количество одновременных вызовов поможет избежать массовых сбоев при высокой нагрузке. Еще одним мощным инструментом для снижения CPU нагрузки в kube-apiserver является конфигурация переменной окружения GOGC, управляющей частотой запуска сборщика мусора. В реальных сценариях повышения этого значения (например, до 200) удавалось снизить время, затрачиваемое на сбор мусора, и сгладить пики загрузки. В итоге, работа с Kubernetes List API в крупных кластерах требует внимательного подхода на всех уровнях — от версии кластера и настройки компонентов, до архитектуры клиентов и контроллеров.