В последние годы крупные языковые модели (LLM) резко изменили подходы к обработке естественного языка и автоматизации разнообразных задач. Их способность понимать и выполнять инструкции стала основополагающей для интеграции в самые разные сферы — от создания контента и бизнес-аналитики до программирования и консультационных сервисов. Однако остается важный и пока мало изученный вопрос — сколько инструкций может одновременно обработать LLM без существенных потерь в качестве выполнения? Этот аспект приобрел критическую значимость по мере того, как системы становятся все сложнее, а требования к их функциональности усиливаются. Новейшее исследование, представленное в работе «How Many Instructions Can LLMs Follow at Once?» («Сколько инструкций могут одновременно выполнять LLM?»), кардинально освещает эту проблему, раскрывая детали и предлагая практические решения. Современные промышленные и исследовательские системы с использованием крупных языковых моделей часто работают с одновременно предъявляемыми десятками и даже сотнями инструкций.
Это связано с необходимостью учета многочисленных требований к формату, стилю, содержанию и специфике создаваемых текстов или решений. При этом локальные или упрощённые бенчмарки традиционно проверяют модели на выполнение лишь нескольких команд, что не отражает реальных условий эксплуатации. Поэтому исследователи разработали новый комплексный бенчмарк IFScale для измерения способности моделей обрабатывать одновременно несколько сотен инструкций, что позволяет провести более глубокий и репрезентативный анализ. IFScale представляет собой набор из 500 инструкций, сформулированных как ключевые слова, которые должны быть включены в бизнес-отчет. Выбор именно подобной бизнес задачи обусловлен её типовой природой: отчеты требуют строгого следования множеству параметров и инструкций, что хорошо отражает реальные сценарии использования LLM.
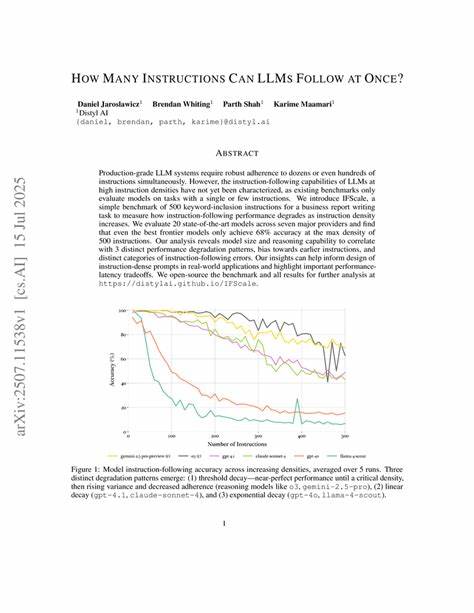
Исследование охватило 20 моделей от семи ведущих провайдеров — что позволяет увидеть общие тенденции и выделить особенности отдельных архитектур и настроек. Основные результаты выявили значительное снижение точности с ростом количества инструкций. Самые передовые модели достигли лишь около 68% точности при максимальном количестве инструкций — 500. Это демонстрирует, что даже самые мощные решения пока далеки от идеального выполнения задачи с экстремально высокой плотностью команд. Анализ выявил три разных паттерна снижения продуктивности и ярко выраженное смещение в пользу более ранних инструкций — модели уделяют им больше внимания, чем инструкциям в конце списка.
Также были обнаружены разнообразные ошибки в следовании инструкциям, которые подразделяются на категории, отражающие особенности обработки и интерпретации команд. Отдельное внимание в исследовании уделено влиянию размера модели и уровня её аналитических способностей. Большие модели с более продвинутыми функциями рассуждения зачастую демонстрируют более устойчивые характеристики и лучше справляются с большим числом инструкций. Однако даже они не застрахованы от падения качества при экстремальных нагрузках, что свидетельствует о фундаментальных ограничениях текущих архитектур и алгоритмов обучения языковых моделей. Одним из важных практических выводов стала рекомендация по составлению и организации инструкций.
Учитывая наличие смещения в пользу первых команд списка, логично оптимизировать инструкции, ставя наиболее важные и критичные в начале, чтобы повысить шансы на их корректное исполнение. Это особенно актуально для бизнес-приложений и автоматизации, где ошибки в ключевых параметрах могут привести к серьезным последствиям. Еще одна находка связана с компромиссами между качеством и временем отклика. При увеличении плотности инструкций модели обеспечивают меньшую точность, но при этом могут работать дольше, что снижает практическую эффективность. Задача балансирования этих величин без ущерба для стабильности результата — одна из важнейших на пути к внедрению LLM в реальном масштабе.
Исследование также открывает множество направлений для дальнейших разработок. В частности, необходимы улучшенные методы масштабирования моделей и повышение избирательной внимательности к каждому отдельному указанию. Исследователи подчеркивают важность развития архитектур с адресуемой памятью и контекстным пониманием, что позволит моделям удерживать и верно применять большое количество инструкций. Для разработчиков ИИ и заказчиков технических решений понимание ограничения LLM в плане одновременного следования множеству инструкций помогает принимать более обоснованные решения при проектировании систем. Например, создание нескольких этапов взаимодействия с моделью, разбивка задач на части и использование вспомогательных алгоритмов для проверки и корректировки ответов – все это способы повысить конечное качество при масштабной работе.
Рынок и сообщество ИИ активно развиваются, и важной частью этого процесса является открытость исследований и доступность данных. В данном случае авторы работы открывают полный бенчмарк IFScale и все результаты для дальнейшего анализа, что стимулирует сотрудничество и ускоряет эффект научного прогресса. Новая эра машинного интеллекта требует тонкого баланса между производительностью, точностью и адаптивностью моделей. Исследование предельных возможностей современных LLM в выполнении множества инструкций одновременно является значимым шагом в понимании текущих проблем и выработке стратегий их преодоления. Это, в конечном счете, позволит создавать более надежные, мощные и гибкие интеллектуальные системы, способные качественно выполнять сложные задачи в разнообразных сферах человеческой деятельности.
Таким образом, хотя современные крупные языковые модели демонстрируют впечатляющие возможности, количество инструкций, которые они могут эффективно обработать одновременно, находится под серьезными ограничениями. Для достижения настоящего масштаба индустрии и обеспечения надежной работы ИИ-систем следует учитывать выявленные ограничения, использовать разработанные бенчмарки для оценки и непрерывно совершенствовать алгоритмическую базу. Ведь именно умение соблюдать множество одновременных требований – ключ к продуктивному и безопасному применению искусственного интеллекта в будущем.