Большие языковые модели (LLM) сегодня становятся фундаментальной технологией для создания интеллектуальных агентов, способных выполнять сложные задачи, такие как взаимодействие с командной строкой, использование разнообразных инструментов, а также управление и анализ веб-контента и других сложных данных с длинным контекстом. В отличие от чатботов, где контекст чаще всего ограничен несколькими десятками или сотнями токенов, задачи агентных LLM требуют работы с контекстом, насчитывающим тысячи и даже десятки тысяч элементов. Этот значительный объем данных создает уникальные вызовы для аппаратных платформ, осуществляющих инференс, в частности ограничения, связанные с пропускной способностью и емкостью памяти, известные как "памятные стены" (memory walls). Эти проблемы существенно снижают эффективность использования вычислительных ресурсов и ограничивают производительность моделей. Для решения данных проблем исследователи разработали PLENA - аппаратно-программную систему, ориентированную на оптимизацию инференса долгоконтекстных агентных LLM.
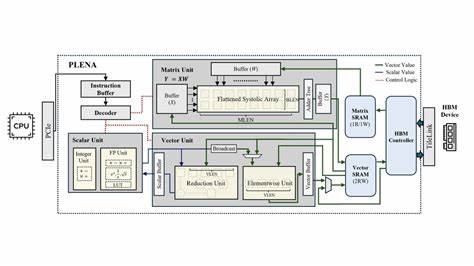
Основная цель PLENA заключается в преодолении ограничений традиционных архитектур и радикальном повышении пропускной способности и эффективности при обработке больших объемов данных в режиме реального времени. Одна из ключевых особенностей PLENA - аппаратная реализация вычислительных и модулярных блоков памяти с поддержкой асимметричной квантования. Это позволяет значительно уменьшить объем данных, передаваемых между процессором и памятью, сохраняя при этом точность вывода модели. В архитектуре предусмотрен новый тип плоского соксального массива (flattened systolic array), который нативно интегрирован с FlashAttention - инновационной технологией оптимизации обработки внимания в нейросетевых моделях, сокращающей задержки и снижая требования к памяти. FlashAttention позволяет эффективнее работать с длинными последовательностями, минимизируя обращения к внешней памяти и значительно ускоряя вычисления.
Помимо аппаратных инноваций PLENA включает полный стек программного обеспечения, который охватывает разработанный с нуля специализированный набор команд (ISA), компилятор, симулятор, эмулирующий циклы работы, и автоматизированный процесс исследования проектного пространства. Такой комплексный подход позволяет не только реализовать аппаратные оптимизации, но и эффективно планировать и адаптировать вычислительные процессы под конкретные задачи моделей LLM с длинным контекстом. Симуляционные результаты показывают, что PLENA обеспечивает до 8.5 раз большую загрузку вычислительных ресурсов в сравнении с существующими ускорителями, а также превосходит по пропускной способности современные GPU и TPU с тем же объемом подключения и памяти (в 2.24 и 3.
85 раза соответственно). Эти данные свидетельствуют о существенном прорыве, который может положительно сказаться на внедрении агентных LLM в промышленных и коммерческих приложениях, где важна скорость обработки и возможность работать с большими объемами данных на лету. Адресованная задачам PLENA область имеет особую значимость с учетом нарастающего интереса к агентным системам, способным управлять сложными процессами и взаимодействовать с различными внешними источниками информации в режиме реального времени. Традиционные архитектуры либо не справляются с необходимыми объемами контекста, либо требуют слишком много ресурсов, что не всегда приемлемо для практического применения. В этом плане PLENA открывает путь к созданию более мощных, масштабируемых и энергоэффективных решений.
Успех PLENA основан на глубокой оптимизации сразу на нескольких уровнях. С одной стороны, аппаратное обеспечение заточено под ускорение работы с памятью и вычислительными блоками, минимизируя узкие места, связанные с передачей данных. С другой стороны, программное обеспечение нацелено на максимальное эффективное использование доступных ресурсов, автоматизируя процессы компиляции и тестирования приложений. Кроме того, открытость и планируемое открытое распространение всей системы позволяет сообществу разработчиков и исследователей быстро внедрять улучшения и адаптировать решение под новые требования. В перспективе можно ожидать дальнейших инноваций, связанных с расширением поддержки различных моделей LLM и интеграцией дополнительных алгоритмов сжатия данных и оптимизации вычислений.
Также важным направлением развития станет адаптация PLENA под новые аппаратные платформы, такие как специализированные чипы для искусственного интеллекта и гибридные системные архитектуры. В целом, PLENA представляет собой пример того, как сочетание аппаратных и программных инноваций способно радикально изменить подход к решению задач длительного контекста и агентных систем. Такой подход может стать новым стандартом для построения инфраструктуры, необходимой для высокопроизводительного инференса сложных моделей, обеспечивая их доступность и эффективность для широкого круга приложений. Индустрия искусственного интеллекта стоит на пороге нового этапа, и решения, подобные PLENA, играют ключевую роль в развитии технологий, способных полностью раскрыть потенциал больших языковых моделей в реальных условиях, с соблюдением требований скорости, точности и масштабируемости. Это важный шаг к созданию умных агентных систем, которые смогут выполнять все более сложные и ответственные задачи, открывая новые горизонты в области автоматизации, анализа данных и взаимодействия человека с машиной.
.