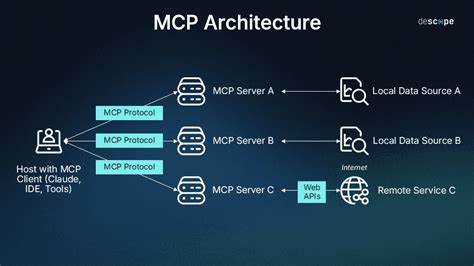
Современные большие языковые модели (LLM) требуют качественного и объемного контекста для эффективного функционирования. Однако в работе с большими объемами данных часто возникает проблема избыточной информации и необходимости фильтрации неактуальных частей данных. Именно здесь на помощь приходит JSON MCP — мощный инструмент, который позволяет оптимизировать работу с JSON-данными, минимизируя шум в контексте, что повышает производительность и точность LLM. JSON MCP — это сервер, реализующий протокол Model Context Protocol (MCP), предназначенный для эффективной работы с JSON-данными. Он обеспечивает автоматическую генерацию TypeScript-схем из реальных JSON-структур и предлагает инструменты для интеллектуальной фильтрации данных, как для локальных файлов, так и для удаленных источников по HTTP и HTTPS.
Основная задача JSON MCP — извлекать из массивных данных лишь те элементы, которые релевантны текущей задаче модели, исключая лишние шумы и ускоряя обработку. Одной из ключевых функций JSON MCP является генерация схем из JSON. С помощью библиотеки quicktype сервер превращает привычные JSON-массивы и объекты в четко типизированные интерфейсы TypeScript. Это не только облегчает разработчикам работу с данными, гарантируя типовую безопасность, но и позволяет более точно задавать структуру фильтрации и запросов. Например, перед началом обработки большого массива пользователей можно создать описание выбранных полей, которые актуальны для модели — имя, email или идентификатор — и исключить все прочие, лишние данные.
Другой важный аспект JSON MCP — интеллектуальная фильтрация, основанная на так называемом shape-based фильтре. Это значит, что разработчик задает шаблон, представляющий интересующие его поля, включая вложенные объекты и массивы. JSON MCP применяет этот шаблон к исходным данным, возвращая только нужные части структуры. Поддержка вложенных объектов и массивов значительно повышает гибкость инструмента и позволяет работать с очень сложными и разветвленными JSON-структурами, которые часто встречаются в ответах API и больших локальных файлах. Дополнительно JSON MCP поддерживает работу с большими объемами данных за счет встроенной системы автоделения на чанки размером до 400 КБ.
Если JSON-объект превышает этот порог, сервер разбивает его на последовательные части, которые можно загружать и обрабатывать поэтапно. Это особенно важно для предотвращения переполнения памяти и снижения времени отклика, что крайне востребовано при интеграции с LLM, где быстрый и безопасный доступ к данным — залог успешной работы. Безопасность и защиту памяти в JSON MCP реализована через лимит в 50 МБ для всех источников данных. При превышении этого порога запросы автоматически блокируются с выдачей информативного сообщения об ошибке. Кроме того, перед загрузкой больших файлов происходит проверка заголовков Content-Length, что позволяет избежать ненужной загрузки избыточных и потенциально вредоносных данных.
JSON MCP отлично интегрируется с платформами Claude Desktop и Claude Code, которые широко применяются для работы с большими языковыми моделями. Интеграция выполняется с помощью стандартизированного конфигурационного файла или командной строки, что обеспечивает гибкость и удобство внедрения в существующие рабочие процессы. Прямое взаимодействие с Claude MCP-серверами позволяет бесшовно подмешивать фильтрованные и типизированные данные в контекст модели, улучшая качество генерации текста и восприятия информации. С точки зрения разработчиков, JSON MCP предлагает готовый набор команд для локальной установки, быстрого старта и отладки. Можно запускать сервер с помощью NPX без необходимости глобальной установки, что экономит время и ресурсы.
При работе с исходным кодом доступны инструменты для сборки, тестирования и инспекции, в том числе интерактивный интерфейс для отладки стратегий загрузки и фильтрации. Проект имеет хорошо организованную структуру с четким разделением по функциональности — главный файл сервера, стратегии загрузки (например, локальные файлы или HTTP-запросы), управлением контекстом и типами данных. Такое архитектурное решение повышает масштабируемость и упрощает доработку, что важно для долгосрочного поддержки и расширения функционала. Важным плюсом JSON MCP является продуманная обработка ошибок и предоставление подробной информации для отладки. Если возникает проблема при работе с локальными файлами или сетевыми запросами, пользователь получает понятные сообщения, в том числе об ошибках авторизации, превышении лимитов, несовместимости форматов.
Это облегчает диагностику и ускоряет устранение проблем. Производительность JSON MCP оптимизирована для разных размеров данных. Для небольших файлов до 100 КБ тайминг обработки практически незаметен — менее 10 миллисекунд. При работе с объемами в несколько мегабайт время растет до одной секунды, что остается приемлемым для большинства сценариев. При превышении 50 МБ сервер блокирует загрузку, гарантируя безопасность и предотвращая сбои.
Рассматриваемое решение оптимально подходит для фильтрации больших JSON-ответов от API, статических файлов и данных локальной разработки. При интеграции с LLM оно позволяет значительно сократить контекстную нагрузку, что ведет к уменьшению времени отклика и повышению точности генерации. Пользователи могут предварительно запускать dry-run анализ для оценки размера и разбиения данных перед фактическим применением фильтров, что делает работу предсказуемой и удобной. Все эти возможности делают JSON MCP важным инструментом в арсенале современных разработчиков и специалистов по обработке естественного языка. Он решает фундаментальную задачу изолирования релевантной информации из больших и сложных структур JSON, сохраняя при этом безопасность и высокую производительность.