Сегодняшние приложения все чаще сталкиваются с необходимостью быстрых и эффективных запросов, особенно когда речь идет о данных, представленных диапазонами. В PostgreSQL, одной из самых популярных и мощных систем управления базами данных с открытым исходным кодом, существует множество техник оптимизации таких запросов. Правильный выбор стратегий индексирования и типов данных может существенно изменить опыт работы с базой — от медленных сканирований до мгновенных ответов с минимальной нагрузкой на систему. Рассмотрим типичную задачу, актуальную для многих разработчиков и инженеров: требуется определить, какие эксперименты или функции активны для определенной мобильной платформы и конкретного номера сборки приложения. С помощью SQL-запроса с условием проверки вхождения значения в диапазон это обычно выглядит так: где платформа равна заданному значению, и номер сборки находится между минимальным и максимальным значением, определяющим диапазон активности.
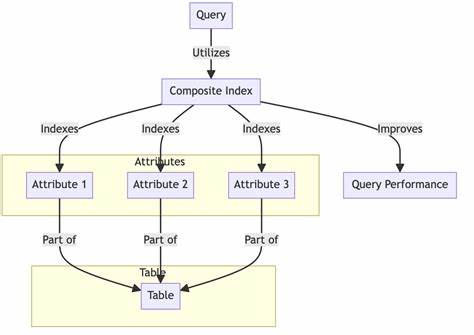
На первый взгляд задача простая, однако при увеличении объемов данных и частоте запросов на первый план выходит вопрос оптимизации. Без индексов серверу баз данных приходится выполнять полное сканирование таблицы — операция, затрачивающая значительные ресурсы и время. Особенно это критично в мобильных приложениях и системах с высокими требованиями к производительности. Одним из наиболее интуитивных подходов является использование составных B-tree индексов, где индекс создается по сочетанию колонок, например, по платформе и минимальному значению диапазона. Такой индекс хорошо работает в случае точечных запросов или поиска по первому элементу.
Однако для условий, где ищется значение внутри диапазона (что типично для BETWEEN), эффективность значительно снижается, поскольку B-tree индекс не предназначен для поиска по диапазонным значениям напрямую. Переходя к более продвинутым решениям, PostgreSQL предлагает возможность использования GiST (Generalized Search Tree) индексов, которые разработаны для работы с пространственными и диапазонными типами данных. GiST является обобщенной структурой, позволяющей построить индексы для различных типов данных, включая интервалы и геометрию. За счет специальной логики сравнения и организации деревьев GiST значительно эффективнее справляется с поиском пересекающихся или содержащихся в диапазоне значений. Чтобы максимально использовать возможности GiST, рекомендуется применять тип данных диапазона, встроенный в PostgreSQL — например, int4range или numrange для числовых данных.
Такие типы позволяют явно указывать нижнюю и верхнюю границу, упрощают запросы и логическим образом отражают условия поиска. Создание GiST индекса по колонке с типом диапазона позволяет базе данных использовать специализированные алгоритмы для поиска пересечений, тем самым ускоряя выполнение запросов с условиями, похожими на BETWEEN. Стоит отметить, что при миграции на GiST индексы важна тщательная оценка схемы данных и особенностей нагрузки. Некоторые типы запросов и структура таблиц могут потребовать комбинирования разных стратегий. Например, в ряде случаев целесообразно применять составные индексы, где сначала фильтруется по платформе с помощью B-tree, а затем — по диапазону с помощью GiST.
Такое сочетание позволяет оптимизировать план выполнения и избежать излишней нагрузки на систему. Кроме того, во многих сценариях полезно использовать расширения PostgreSQL, обеспечивающие дополнительную функциональность и оптимизации. Например, расширение pg_trgm иногда применяется для поиска по тексту, а для специфичных диапазонных запросов существуют и собственные решения сообщества, которые могут улучшить время отклика и снизить затраты на обслуживание. В реальной практике важное значение имеют также мониторинг и профилирование запросов. Использование средств анализа, таких как EXPLAIN и pg_stat_statements, позволяет выявить узкие места и принять обоснованные решения по корректировке индексов и реорганизации данных.
Регулярное обновление статистики и анализ выполнения запросов помогают поддерживать высокий уровень производительности даже при динамически меняющихся нагрузках. Еще одним важным аспектом является выбор правильного типа данных для хранения диапазонов. В некоторых случаях числовые поля лучше заменить на диапазонные типы PostgreSQL, что упрощает запросы и повышает эффективность индексации. Также стоит учитывать особенности бизнес-логики и возможные варианты изменений в будущих версиях приложения — гибкость и расширяемость схемы базы данных являются залогом долговременного успеха. В итоге, успешная оптимизация запросов по диапазонам в PostgreSQL — это баланс между пониманием внутренних механизмов СУБД, правильным выбором индексных структур и тщательным дизайном схемы данных.
Постепенное изучение возможностей, от классических составных B-tree индексов до продвинутых GiST индексов, позволяет построить устойчивую и быструю систему, способную эффективно обрабатывать большие объемы информации и обеспечивать удобный и быстрый доступ для пользователей. Для разработчиков и администраторов стоит также помнить, что технический долг, если его своевременно не ликвидировать, со временем приведет к деградации производительности. Инвестиции в правильную архитектуру базы данных и регулярный аудит запросов окупаются многократно за счет ускорения работы приложений и сокращения времени простоя. Таким образом, PostgreSQL предоставляет мощный инструментарий для оптимизации запросов по диапазонам, и грамотное его применение открывает широкие возможности для построения масштабируемых, надежных и быстрых систем хранения и обработки данных.