Искусственный интеллект сегодня проник практически во все сферы нашей жизни — от составления писем и планирования поездок до научных исследований и творческих проектов. И хотя возможности ИИ расширяются с каждым днем, мало кто задумывается об экологических последствиях постоянного и массового использования таких технологий. Последние исследования показывают, что одни запросы к ИИ могут вызывать выбросы углекислого газа в 50 раз больше, чем другие. Это открывает новый ракурс понимания воздействия цифровых технологий на климат и стимулирует обсуждение о необходимости оптимизации процессов и моделей искусственного интеллекта с учетом энергоэффективности. В статье подробно разберем, почему происходит такая разница в выбросах, как параметры моделей, типы задач и ответы влияют на углеродный след, а также рассмотрим вызовы, которые стоят перед разработчиками и пользователями ИИ сегодня.
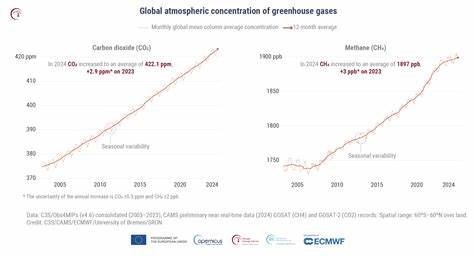
Современные вычислительные центры, обеспечивающие работу и обучение больших языковых моделей, потребляют огромные объемы электроэнергии. Согласно данным Международного энергетического агентства, дата-центры в США в 2023 году использовали около 4,4% всей электроэнергии страны, а прогнозы свидетельствуют о росте этого показателя до 6,7–12% к 2028 году. Параллельно с этим количество глобальных дата-центров выросло с 500 тысяч в 2012 году до более 8 миллионов уже в 2024 году. Такие масштабные ресурсы необходимы для обработки многочисленных запросов к ИИ, но они вносят значительный вклад в выбросы парниковых газов. Несмотря на то что измерить точное потребление энергии отдельно взятой задачи искусственного интеллекта пока сложно, исследования начинают выявлять закономерности влияния различных типов запросов.
В частности, одна из последние научных работ, опубликованная в журнале Frontiers, анализировала объемы «токенов» — минимальных единиц данных, которые языковые модели используют для генерации ответов. В работе выяснилось, что запросы, требующие сложного рассуждения и глубокого анализа, сильно увеличивают количество токенов, что напрямую связано с ростом энергопотребления и, соответственно, выбросов CO2. Это связано с тем, что сложные задачи, например, философские размышления или абстрактная математика, подразумевают гораздо более объемный и многоэтапный алгоритм рассуждений. Такие модели создают на 50 раз больше углеродного следа по сравнению с простыми или стандартными запросами вроде школьной истории или быстрого поиска данных. Таким образом, вопрос не только в частоте использования ИИ, но и в выборе типа запроса и функциональности модели.
Анализ 14 различных больших языковых моделей показал, что число параметров модели и их способность к сложным рассуждениям влияют на объем выбросов. Модели с высокими параметрами и улучшенными логическими способностями, к примеру Cogito, выдают гораздо более точные ответы, но при этом их углеродный след в три раза выше, чем у менее сложных моделей, которые дают более краткие и энергоэффективные ответы. Такой баланс между точностью и экологичностью называют «компромиссом между точностью и устойчивостью». На данный момент ни одна модель, которая сокращает выбросы CO2 более чем до 500 грамм эквивалента на запрос, не достигает уровня точности свыше 80% на тестовых вопросах. Это накладывает вызовы на разработчиков и ученых, которым предстоит разрабатывать алгоритмы, позволяющие минимизировать потребление энергии, не жертвуя качеством информации.
Кроме параметров модели и сложности задачи, разница в углеродных выбросах также определяется архитектурными особенностями конкретных систем ИИ. Разные языковые модели популярны и используют от нескольких до десятков миллиардов параметров, при этом показатели энергоэффективности у них могут сильно отличаться. Так, модель DeepSeek R1 с 70 миллиардами параметров, отвечая на 600 тысяч вопросов, создаст объем выбросов CO2 сопоставимый с авиаперелетом из Лондона в Нью-Йорк и обратно. В то же время модель Qwen 2.5, имеющая 72 миллиарда параметров, способна обработать приблизительно в три раза больше запросов при таком же уровне выбросов.
Это указывает на то, что не только размер модели, но и эффективность ее настроек и алгоритмов чрезвычайно важны для снижения экологического следа. Эксперты подчеркивают, что осведомленность пользователей о воздействии ИИ на климат крайне важна. Если люди будут понимать, сколько энергии тратится на определенные типы заданий и каких выбросов это приводит, они смогут осознанно подходить к выбору запросов и частоте их использования. Стремление к более эффективной эксплуатации ИИ позволит сократить нагрузку на дата-центры и уменьшить экологический вред. С другой стороны, индустрия искусственного интеллекта сталкивается с необходимостью инвестировать в развитие зеленых вычислительных технологий и инноваций, направленных на повышение энергоэффективности.
Это могут быть новые архитектуры нейросетей, оптимизация кода, перенос вычислений на более энергоэффективные серверы и переход на возобновляемые источники энергии в дата-центрах. Уже сейчас многие крупные технологические компании акцентируют внимание на устойчивом развитии и отвечают за снижение углеродного следа своих продуктов. Важно также учитывать, что растущий спрос на модели ИИ связан с тем, что текстовые и мультимедийные генеративные технологии активно влияют на образование, бизнес, искусство и коммуникацию. Продолжительный рост количества запросов и усложнение задач рискуют увеличить энергетическое потребление и выбросы, если не будет внедрено постоянное отслеживание и регулирование. Общество, ученые и разработчики должны совместно искать баланс между инновациями и экологическими приоритетами.