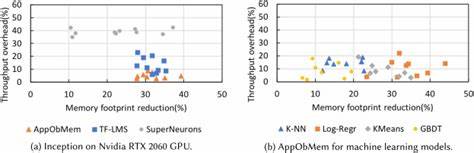
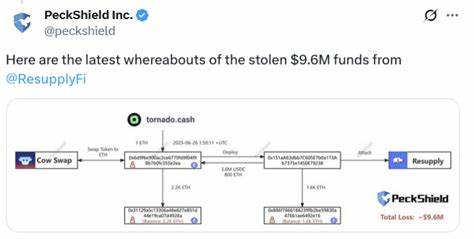
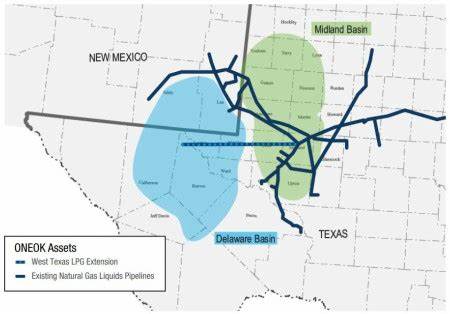
В последние годы искусственный интеллект (ИИ) перестал быть только концепцией из научной фантастики и превратился в реальность, которая активно меняет бизнес-процессы и нашу повседневную жизнь. Одной из ключевых технологий современности стали большие языковые модели (LLM), обучающиеся на огромных объемах текстовой информации. Однако именно использование этой информации вызывает многочисленные юридические споры — авторы и правообладатели все чаще обвиняют разработчиков ИИ в нарушении авторских прав путем обучения на копиях их произведений без разрешения. Одним из громких примеров в этой сфере стало судебное дело между Meta, гигантом в области технологий, и группой авторов, включая таких известных писателей, как Ричард Кадри, Сара Сильверман и Кристофер Голден. Они обвинили компанию в «пиратстве», утверждая, что Meta использовала библиотеки нелегально скачанных книг для обучения своих языковых моделей.
Дело приобрело общественное значение, поскольку поднимает сразу несколько острых тем: можно ли считать использование авторских материалов для создания тренированных ИИ-моделей допустимым без лицензионных соглашений и что именно подразумевается подfair use (справедливое использование) в эпоху цифровых технологий. Meta открыто признала, что использовала эти книги, полученные из теневых библиотек через протокол BitTorrent, для обучения своей модели Llama. Однако в ответ на обвинения компания заявила, что действия соответствуют принципам справедливого использования, и представила своё видение данного вопроса в ходе рассмотрения в суде. Рассмотрение дела дошло до стадии, когда обе стороны подали ходатайства о частичном вынесении решения без полного судебного разбирательства, пытаясь убедить суд в обоснованности своих позиций. Meta настаивала, что использование авторских произведений для обучения языковой модели является трансформирующим и не наносит вреда рынку оригинальных произведений.
Авторы, напротив, утверждали, что массовое скачивание книг было незаконным и не может считаться fair use, а также что из-за этого они лишились доходов от лицензий. В марте 2025 года судья Винс Чхабрия вынес постановление, которое стало частичной победой для компании Meta. Суд отклонил требования авторов о признании Meta виновной в прямом нарушении авторских прав, связанных с загрузкой пиратских книг с использованием BitTorrent, а также подтвердил, что обучение языковой модели на этих данных нужно рассматривать как fair use. В центре решения суда оказалось правильное понимание факторов fair use, где отдельное внимание уделялось потенциальному ущербу рынку — ключевому критерию для определения правомерности использования материалов. Суд отметил, что использование книг для обучения модели имеет «трансформирующую» природу, поскольку искусственный интеллект не копирует тексты напрямую, а создает новые контенты на их основе, предназначенные для решения разнообразных задач.
Аргументы авторов, что Llama могла воспроизводить большие фрагменты текстов, оказались неубедительными — экспертные заключения показали, что ИИ не способен генерировать более 50 слов подряд из оригинальных произведений, даже при целенаправленных запросах, направленных на выявление такого копирования. Кроме того, заявление об утрате рынка лицензирования на обучение ИИ также было отвергнуто за отсутствие юридического признания такого ущерба. Интересное внимание суд уделил теории рыночного размывания — идее о том, что модели ИИ могут создавать множество произведений, которые конкурируют с оригиналами, даже если сами генерации не считаются прямым нарушением авторских прав. Суд отметил, что именно этот аспект представляет значительную угрозу рынку, поскольку избыток похожих и альтернативных контентов способен подорвать спрос на оригинальные работы. Тем не менее, авторы не смогли предоставить достаточных доказательств в поддержку этой теории, что и стало одним из оснований для вынесения решения в пользу Meta.
Несмотря на кажущуюся победу Meta, судья Чхабрия дал понять, что дело далось компании не без оговорок. Речь идет лишь о решении по отдельным пунктам и в отношении только тех авторов, которые участвовали в деле. Заявление о полной законности использования авторских материалов для обучения ИИ еще не сделано, что оставляет пространство для будущих судебных споров. Более того, суд поддержал идею о возможной необходимости лицензирования контента в будущем, при этом отклонив соответствующую позицию компании о том, что отрицательное решение «останавливает развитие технологий». Решение суда можно рассматривать как предупреждение для разработчиков ИИ о том, что простое оправдание использования данных без согласия правообладателей не будет являться панацеей.
Компании в технологическом секторе, создающие подобные модели, должны быть готовы либо заключать лицензионные соглашения, либо доказывать отсутствие реального ущерба рынку. В целом, дело Meta отражает сложность баланса между инновациями в области ИИ и защитой авторских прав в цифровую эпоху. Оно поднимает фундаментальные вопросы того, как законодательство и судебная практика будут соотноситься с быстрыми темпами развития технологий. И пока важно учитывать, что использование огромных массивов данных для обучения искусственного интеллекта должно сопровождаться уважением к правам творцов и ответственной правовой стратегией. Таким образом, решение суда стало важной вехой, но не окончательным финалом в юридическом регулировании ИИ.
Это знак для участников рынка о необходимости внимательного подхода к вопросам лицензирования и справедливого использования данных, а также приглашение к диалогу между законодателями, авторами контента и разработчиками технологий. Будущее искусственного интеллекта в значительной мере будет зависеть от того, как будет устроена эта взаимосвязь и насколько сможет сбалансировать интересы всех сторон.