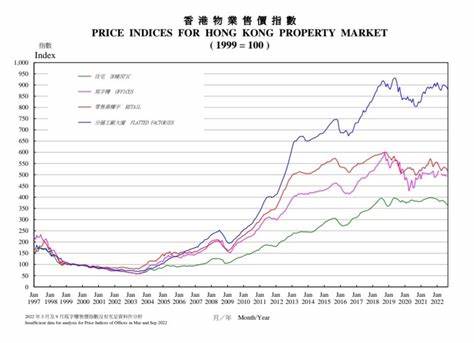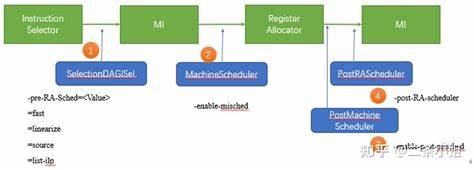
LLVM - одна из самых мощных и гибких инфраструктур для компиляции, предоставляющая множество инструментов для оптимизации и трансформации программного кода на этапе компиляции. Одним из ключевых компонентов LLVM является машинный планировщик (Machine Scheduler), который играет важную роль в организации порядка выполнения инструкций на уровне машинного представления кода. Знание принципов работы машинного планировщика позволяет понимать, как компилятор подбирает оптимальный порядок команд для минимизации задержек и повышения эффективности использования ресурсов процессора. Машинный планировщик LLVM зародился как попытка решать задачу упорядочивания инструкций непосредственно в процессе трансформации программного кода на низком уровне. Идея возникла из потребности оптимизировать "линейный" набор инструкций - Machine IR, представление, где все машинные команды расположены в виде последовательностей, но с чёткими зависимостями и ограничениями, заданными архитектурой процессора.
Планировщик начал развиваться спустя некоторое время после внедрения SelectionDAG, его предшественника, который оперировал на уровне направленных ацикличных графов (DAG) ещё во время этапа instruction selection. Однако практика показала, что эффективнее перенести фазу планирования позже по конвейеру компиляции - ближе к моменту, когда уже произведены оптимизации на уровне Machine IR, но ещё до основных этапов выделения регистров. Такой сдвиг позволил лучше учитывать реальные ограничения архитектуры и оптимально распределять нагрузку между функциональными блоками процессора. Главной задачей машинного планировщика служит максимальное снижение регистрового давления и повышение параллелизма инструкций. Для снижения регистрового давления важно минимизировать перекрытие живых диапазонов, что снижает вероятность необходимости использования локальных сторедж-слотов памяти и, как следствие, частоту вынужденных сохраниений и восстановлений регистров (spill/reload).
Второй приоритет - улучшение уровня параллелизма, выраженное в эффективном сокрытии задержек между зависимыми инструкциями и избегании простоев, вызванных ограничениями на доступ к ресурсам процессора, таким как конвейеры вычислительных блоков и очередей выдачи команд. Основным инструментом внутри машинного планировщика является структура данных ScheduleDAGInstrs, представляющая отдельный базовый блок в виде ориентированного ацикличного графа, узлы которого - это отдельные машинные инструкции (представленные структурами SUnit). Каждая такая вершина содержит информацию о своих предшественниках и потомках, отражающих зависимости данных и порядок выполнения для сохранения корректности программы. Важной характеристикой каждого узла являются latency (задержка), height и depth. Задержка описывает время ожидания результата вычисления данной инструкции, height - максимальную сумму задержек по критическому пути от текущего узла к концам графа, а depth - аналогичный параметр в обратном направлении.
Эти метрики позволяют планировщику применять алгоритмы топологического прохождения графа либо в топ-даун, либо в боттом-ап режиме, обеспечивая максимальную гибкость и адаптацию к различным стратегиям. Процесс самого планирования можно сравнить с моделированием виртуального временного графика, на котором шаг за шагом размещаются инструкции с учётом текущего цикла исполнения (CurrCycle), ресурсов процессора и устранения конфликтов. Виртуальный таймлайн отражает текущую фазу планирования, позицию, на которой рискуется разместить следующую команду с учётом возможностей компромисса между разрешением зависимостей и занятостью ресурсов. LLVM Machine Scheduler поддерживает два типа очередей кандидатов: pending и available. Кандидаты в pending находятся в режиме ожидания с учётом несовершенств либо ограничений, например, зависимости от данных, ещё не исполненных инструкций или занятости ресурсов.
Кандидаты, успешно прошедшие проверку на свободное исполнение, переходят в available - отсюда планировщик выбирает наилучший вариант для размещения. Поиск оптимальной инструкции для следующего шага является ключевой частью работы, учитывая балансировку нагрузки, уменьшение регистрового давления и минимизацию простоев. Для оценки качества выбора в Machne Scheduler применяется ряд критериев, направленных на обеспечение выгодного порядка. Преимущество отдаётся инструкциям с меньшим регистровым давлением, минимальным "мягким" простоем ("soft stalls") на устройствах с латентностью, низкой нагрузкой на ресурсы и минимальной задержкой, а при равенстве условий - сохранению исходного порядка команд. Особое внимание уделяется обнаружению и предупреждению "hazards" - различных затруднений, связанных с исполнением инструкций на уровне данных и структурных ограничений процессора.
Два основных вида hazards - data hazard и structural hazard. Data hazard возникает, когда инструкция пытается использовать данные, которые ещё не готовы из-за задержек в предыдущих вычислениях. Машинный планировщик снабжает каждый узел SUnit полем ready cycle, отражающим момент, когда все его операнды становятся доступными. Это позволяет отложить выполнение тех инструкций, операнды которых ещё не готовы, эффективно предотвращая ожидания и простоев. Structural hazard связан с ограничениями аппаратных ресурсов, например, количеством доступных функциональных блоков для умножения либо сложения.
Машинный планировщик ведёт учёт занятости этих ресурсов с помощью массива ReservedCycles, определяющего, до какого цикла ресурс занят и не может быть назначен новой инструкции. Это позволяет избежать конфликтов, когда несколько инструкций конкурируют за один и тот же ресурс. Важно отметить, что для современных архитектур с out-of-order исполнением аппаратный планировщик зачастую выполняет ту работу, которая в LLVM Machine Scheduler была бы связана с обработкой хазардов. В таких случаях планировщик компилятора упрощается, а механизмы детекции заторов отключаются. Однако для in-order архитектур проверка занятости ресурсов и готовности операндов является критической для корректного и эффективного разложения программы.
В ядре LLVM Machine Scheduler лежит взаимосвязь со схемой описания архитектуры - scheduling model. Именно тут определяется, сколько инструкций за такт может быть выпущено (IssueWidth), каковы задержки вычислительных блоков и размер внутренних буферов. Такие параметры, как BufferSize для отдельных ресурсов и MicroOpBufferSize, диктуют, будет ли обнаружениеhazards применяться либо нет и с какой степенью строгости. Обширные настройки scheduling model создают мощный базис для точной эмуляции поведения аппаратных ресурсов, позволяя компилятору тонко настраивать порядок расписания. Благодаря такому подходу LLVM достигает высокого уровня оптимизации на этапе генерации машинного кода, снижая количество потенциальных простоев и одновременно минимизируя нагрузку на регистровый файл.
Архитектура планировщика также поддерживает двунаправленное планирование - top-down и bottom-up - что даёт возможность максимально эффективно распараллелить инструкции, сокращая критические пути и обеспечивая более равномерное распределение нагрузки. Сложность таких алгоритмов компенсируется продуманной организацией внутренних структур и переходов между состояниями кандидатов. Изучение работы машинного планировщика в LLVM открывает глаза на тонкости взаимодействия компилятора и архитектуры процессора. В его основе лежит оптимальный баланс между точностью моделей задержек и ресурсных ограничений с практичностью и быстродействием алгоритмов. Полученные знания помогают разработчикам компиляторов и исследователям лучше понимать, как преобразуется код для достижения максимальной производительности.
В целом, Machine Scheduler является важнейшим компонентом в цепочке генерации кода в LLVM, играя роль "дирижёра" в оркестре инструкций. Его способность управлять порядком выполнения с учётом сложных зависимостей и аппаратных параметров, а также предотвращать задержки и конфликты, обеспечивает высокая эффективность конечных программ и высокий уровень оптимизаций. .