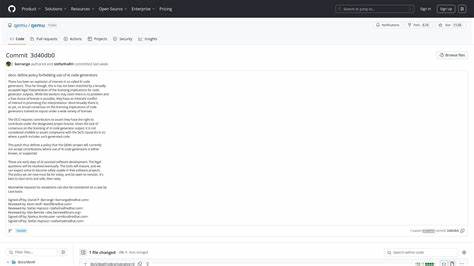
С момента появления и стремительного развития технологий искусственного интеллекта мир разработки программного обеспечения претерпевает значительные изменения. Среди этих нововведений — активное использование ИИ для генерации кода, что открывает широкие возможности для автоматизации и ускорения процессов разработки. Однако не все сообщества открытого программного обеспечения воспринимают эти новшества однозначно. Ярким примером является проект QEMU, который официально запретил принимать вклад с кодом, сгенерированным искусственным интеллектом. Этот шаг вызвал бурные обсуждения и стал отправной точкой для более глобального анализа того, как открытые проекты могут интегрировать искусственный интеллект в процесс разработки, учитывая правовые и технические особенности такого кода.
Основной причиной запрета QEMU является несоответствие кода, созданного ИИ, требованиям, предъявляемым к авторству в Developer’s Certificate of Origin (DCO). DCO требует, чтобы каждый вклад был «создан мной», то есть обладал чётко определённым человеческим авторством. Современное законодательство в большинстве юрисдикций не признаёт за ИИ авторских прав, что создаёт серьёзные проблемы с юридической защитой и установлением ответственности за подобный код. Отсутствие признанного владельца прав практически исключает возможность подтвердить подлинность вклада при помощи текущих методов DCO. Помимо авторства возникает и другая важная проблема — качество и происхождение исходного материала.
ИИ-модели обучаются на большом объёме существующего программного кода, который может иметь разнообразные лицензии, включая несовместимые с лицензией целевого проекта. Это порождает риск случайного включения в итоговый продукт фрагментов, защищённых авторскими правами с ограничениями, что противоречит принципам открытого программного обеспечения и может привести к юридическим конфликтам. Хотя современные методы обнаружения сходств в коде помогают выявлять совпадения с уже опубликованными фрагментами и тем самым снижают риск нарушений лицензионной совместимости, они не могут гарантировать полного отсутствия проблем. Кроме того, вопрос определения авторства остаётся фундаментальным и гораздо более сложным для решения. Интересно, что в ряде стран отсутствует единое правовое понимание статуса ИИ-сгенерированного кода.
На практике это означает, что при возникновении спорных ситуаций сложно доказать, что конкретный фрагмент был создан полностью машинным интеллектом и не принадлежит никому с авторскими правами. В такой правовой неопределённости безопасность и доверие к ИИ-коду оказываются под вопросом, что вынуждает сообщества открытого ПО быть осторожнее и склоняться к ограничениям, подобным той, что принял QEMU. Тем не менее, полное исключение ИИ-сгенерированного кода из проектов открытого программного обеспечения не является единственным возможным сценарием. Современные технические решения предоставляют реальные варианты для адаптации и развития процесса принятия таких вкладов с необходимыми гарантиями. В первую очередь это касается совершенствования инструментов для сравнения и анализа кода, которые позволяют автоматически выявлять и документировать совпадения с уже существующими исходниками.
На данный момент коммерческие решения в этой области весьма эффективны, однако важна поддержка и развитие открытых аналогов, доступных любым проектам без существенных финансовых барьеров. Для повышения прозрачности использования ИИ в создании кода играет важную роль работа над стандартами, способными чётко маркировать и идентифицировать ИИ-сгенерированный контент. Например, расширение спецификации SPDX, широко используемой для описания лицензионных требований и происхождения программного обеспечения, может включать специальные отметки, указывающие на участие ИИ в создании кода. Это позволит автоматически отслеживать и учитывать специфику таких вкладов на уровне систем управления проектами и репозиториев. Наиболее сложной задачей остаётся адаптация самой юридической базы, а именно Developer’s Certificate of Origin.
Исторически DCO предназначался для подтверждения подлинности вклада и его происхождения от реального человека, особенно в тех проектах, где высокая правовая стабильность критична, как в Linux. Внедрение ИИ в процесс разработки поставило эту систему лицом к лицу с необходимостью пересмотра и модификации её основных принципов. Однако простое обновление DCO опасно подорвать её главные достоинства — простоту и универсальность, а также вызвать путаницу среди участников сообщества. Поэтому сегодня разумным представляется путь создания дополнительных рекомендаций и объяснительных документов, которые помогали бы разработчикам и администраторам проектов ориентироваться в том, как квалифицировать и принимать ИИ-сгенерированные вклады, не нарушая базовые требования DCO, сохраняя при этом её целостность. Такая унификация позволит уменьшить разночтения и повысить доверие в экосистеме открытого кода.
В этой ситуации большую роль может сыграть Linux Foundation, как инициатор и главная сила, стоящая за разработкой и поддержкой DCO. Международная практика показывает, что централизованное руководство практически всегда эффективнее, чем разрозненные усилия отдельных проектов. Предоставление чётких, практичных рекомендаций для проектов, использующих DCO, поможет повысить правовую устойчивость и гибкость сотрудничества в эпоху искусственного интеллекта. Следует отметить, что подходы к использованию ИИ-сгенерированного кода во многом будут зависеть от типа проекта и приоритетов сообщества. Серьёзные системные проекты, где критична стабильность и юридическая ясность, скорее всего, будут сохранять жёсткую позицию, подобную QEMU.
В то же время проекты, ориентированные на быстрый цикл разработки и инновации, смогут экспериментировать с различными уровнями риска, гибко адаптируя политики принятия ИИ-кода. Таким образом, запрет QEMU на ИИ-сгенерированный вклад отражает текущие сложности и вызовы, с которыми сталкивается экосистема открытого программного обеспечения в эпоху искусственного интеллекта. Этот опыт демонстрирует, что для безопасного и эффективного использования ИИ в разработке ПО необходимы комплексные изменения — от технических инструментов для анализа и маркировки кода до серьёзного обновления юридических процедур и стандартов. Подобные меры обеспечат, что инновации на основе ИИ смогут гармонично вписываться в модель открытого сотрудничества, одновременно защищая права всех участников процесса. Нельзя забывать и об образовательной роли сообщества.
Разработчики и юристы должны активно обмениваться знаниями о возможностях и ограничениях ИИ-сгенерированного кода. Это позволит создавать более продуманную и адаптивную среду разработки, где инновации и безопасность идут рука об руку. В конечном счёте, баланс между инновациями и правовыми гарантиями станет фундаментом нового этапа развития открытого программного обеспечения, где искусственный интеллект не будет рассматриваться как угроза, а как мощный инструмент расширения творческих и технических возможностей разработчиков по всему миру.