В современном мире обработки данных наблюдается стремительное развитие технологий, трансформирующих способы хранения, управления и анализа информации. Одна из ярких тенденций последних лет — переход от монолитных дата-складов к децентрализованным архитектурам, где функции хранения и вычислений отделены друг от друга. Однако подобные изменения не обходятся без сложностей, которые открыли поле для новых решений, одним из которых стали открытые форматы таблиц. Внимание к ним растет в связи с вопросом: смогут ли они подвинуть гигантов рынка, таких как Snowflake и Databricks, и как эта трансформация повлияет на всю отрасль аналитики данных? Исторически дата-склады представляли собой единую систему, включающую в себя все: хранение данных, управление доступом, выполнение запросов и администрирование транзакций. Это позволяло пользователям чувствовать себя уверенно, поскольку все процессы интегрированы и стандартизированы.
Однако при переходе в эру облачных технологий традиционный подход начал сталкиваться с серьезными ограничениями. Масштабируемость, стоимость и гибкость стали ключевыми вызовами, которые потребовали переосмыслить архитектуру аналитических платформ. В ответ на это возникла модель, при которой данные хранятся в больших, недорогих распределенных хранилищах, например, Amazon S3, а вычислительные ресурсы подключаются по требованию для выполнения аналитических задач. Несмотря на очевидные плюсы такой раздельной архитектуры, она порождает практические сложности. В частности, облачные хранилища сами по себе — это просто набор файлов без встроенных механизмов управления версиями, транзакциями или контроля доступа на уровне таблиц.
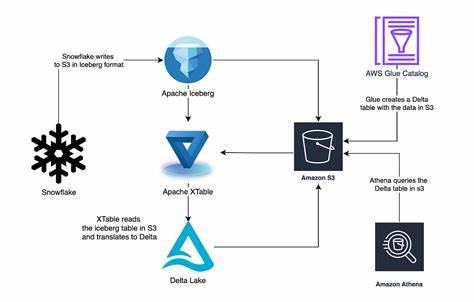
Проще говоря, без дополнительных слоев такой набор файлов не обеспечивает те гарантии, которые дает полноценный дата-склад. Решением этой проблемы стали открытые форматы таблиц — специализированные технологии, призванные реализовать роль "каталога" данных, как в библиотеке, где существует организованная система каталогов для поиска и управления огромными коллекциями книг. Открытый формат таблиц служит своего рода компасом в этом хаосе, позволяя систематизировать, версионировать и отслеживать изменения в данных, сохраненных в облачном хранилище. Ключевые проекты в этой области — Apache Iceberg и Delta Lake, которые обеспечивают высокоуровневый контроль над данными и их метаданными, реализуя поддержку транзакций, снимков и эффективного поиска файлов. Iceberg, в частности, структурирует свои компоненты в четко разделенные слои: хранение данных, хранение метаданных, каталог и механизм запросов.
Такой подход облегчает масштабирование и упрощает интеграцию с разными аналитическими движками. Тем не менее, появилась альтернатива, предлагающая более радикально упрощенный взгляд на проблему — формат DuckLake от команды DuckDB. Этот проект поднял вопрос о необходимости отдельных слоев метаданных и каталога, указав на то, что эти компоненты по своей сути должны вести себя как реляционная база данных с поддержкой транзакций и эффективных индексов. Зачем изобретать сложные специальные форматы, если можно использовать проверенные технологии баз данных для метаданных и каталога? Именно эта идея открывает потенциально новую эру в архитектуре аналитических систем. Она позволяет значительно упростить инфраструктуру, сделав каталоги таблиц легко заменяемыми и расширяемыми, а также снизить издержки на внедрение и поддержку, что становится важным фактором для компаний с ограниченным бюджетом или небольшими объемами данных.
Однако переход к такому открытому и модульному стеку ставит под вопрос доминирование лидеров отрасли — Snowflake и Databricks. Эти компании построили прибыльные бизнес-модели на комплексных, интегрированных решениях, предлагая пользователям «все в одном» с удобными интерфейсами, безопасностью и масштабируемой производительностью. Их каталоги и метаданные выступают не просто технической функцией, а стратегическим элементом, служащим точкой контроля и удержания клиентов в рамках экосистемы. Открытые форматы таблиц и подход DuckLake разрушают эту уникальность, предлагая каждому возможность самостоятельно управлять каталогом и метаданными, использовать различные движки запросов и строить гибкие решения. Это ведет к хаотизации рынка, где ключевым становится не монолитное решение, а совместимость и стандартизация компонентов.
В результате, движки запросов и аналитические платформы рискуют превратиться в универсальные и взаимозаменяемые облачные сервисы или просто ПО с открытым исходным кодом. Для крупнейших облачных провайдеров, таких как Amazon, Google и Microsoft, подобная ситуация — выгодный сценарий, поскольку они продают вычислительные ресурсы и хранилища. Коммодитизация вычислительных движков запросов усиливает конкуренцию и снижает цены, что выгодно конечным пользователям. В то же время для Snowflake и Databricks такая эрозия ценностей может означать потерю контроля над клиентской базой и ухудшение финансовых показателей. В условиях конкуренции снизу со стороны новых игроков, использующих дешевое облачное хранилище и легковесные, быстрые решения вроде DuckLake, возникает потенциальный рынок для бюджетных аналитических платформ, ориентированных на более простые задачи и меньшие объемы данных.
Такие решения могут заинтересовать компании, которым не нужны премиальные функции или высокая производительность, а важна именно экономия и гибкость. Примером может стать Cloudflare с их R2 и D1, которые могут создать доступный комплекс решений, использующий открытые форматы и стандарты нового поколения. Тем не менее для крупных корпораций с высокими требованиями к безопасности, поддержке и интеграции полный переход на открытые форматы и «разборные» архитектуры потребует времени и усилий. Им важно сохранить гарантии целостности данных, а также центральную точку ответственности — то, что предлагает готовый комплекс от известного поставщика. Это объясняет, почему бизнес-модель полноценных дата-складов сохраняет обороты и почему революция в отрасли не произойдет одномоментно.
Подводя итоги, можно сказать, что открытые форматы таблиц и декомпозиция дата-складов открывают путь к большей гибкости, стандартизации и снижению затрат. Они потенциально могут снизить зависимость от крупных поставщиков облачных аналитических платформ и стимулировать появление новых игроков с альтернативными решениями. При этом, усиливающаяся коммодитизация движков запросов и каталогов изменит баланс сил и бизнес-модели, заставив лидеров рынка адаптироваться к новым реалиям. Поколение новых форматов файлов, каталогов и метаданных представляет собой мощный сдвиг в архитектуре аналитики данных, способный сделать технологии более доступными и унифицированными. В то же время, господство Snowflake и Databricks еще не подорвано окончательно — сражение продолжается, и оно задаст тон развитию всей отрасли в ближайшие годы.
Для бизнеса это время уникальных возможностей, когда можно переосмыслить подход к аналитике и построить решения, максимально соответствующие конкретным задачам и бюджету.