В современном мире управления информационными технологиями масштаб инфраструктур становится всё больше, и ручной мониторинг перестаёт быть эффективным и безопасным. Puppet давно зарекомендовал себя как мощное средство управления конфигурациями и сбора данных, однако для того, чтобы получать из него максимальную пользу, требуется грамотная визуализация и обработка собранной информации. Интеграция Puppet с Grafana через Observability Data Connector предоставляет уникальную возможность получать полный обзор состояния систем в реальном времени, анализировать тренды и принимать обоснованные решения на основе данных. Observability Data Connector — это премиальный модуль, входящий в пакет Puppet Enterprise Advanced. Он позволяет экспортировать метрики и данные, собранные Puppet, в формате, который легко интегрируется с популярными инструментами мониторинга, в частности с Prometheus и Grafana.
Данная связка расширяет возможности администраторов и DevOps-команд, позволяя не только следить за работоспособностью отдельных узлов и сервисов, но и оперативно выявлять аномалии и узкие места в инфраструктуре. Ключевым преимуществом использования Observability Data Connector является автоматизация процесса экспорта данных. Модуль собирает информацию о каждом Puppet-агенте, включая факты об окружении, проверки состояний и результаты выполнения конфигураций, и сохраняет их в формате Prometheus. Эти данные потом становятся доступны через HTTP-интерфейс, который можно настраивать и расширять под нужды команды. Благодаря такому подходу информация становится доступнее и проще для интеграции с системами визуализации.
Установка Observability Data Connector начинается с добавления модуля в репозиторий управления. Для Linux-систем рекомендуется использовать Puppetfile, где указывается актуальная версия модуля с Puppet Forge. После развертывания модуля на Puppet-сервере создаётся кастомный профильный класс, в котором задаются основные параметры, такие как drop zone — директория для хранения экспортируемых данных, и stale time — время, по истечении которого неактивные узлы считаются устаревшими. Такой подход способствует гибкой настройке и адаптации под конкретные требования инфраструктуры. Следующим шагом выступает классификация сервера Puppet на уровне интерфейса Puppet Enterprise Console.
Создается специализированная группа для наблюдения за всеми необходимыми узлами, куда добавляется сервер Puppet с ранее созданным профильным классом. Это позволяет централизованно управлять настройками мониторинга и обеспечивает прозрачность установки для всей команды. После развертывания модуля важно проверить корректность сборки и выгрузки данных. В стандартной конфигурации экспорт происходит в заранее заданную директорию. Данные представляют собой набор файлов в формате yaml с метриками, структурированными под Prometheus — это универсальный формат, совместимый с многочисленными инструментами аналитики и визуализации.
Для того чтобы Grafana могла полноценно использовать эти данные, необходим дополнительный компонент — сервер Prometheus. Он отвечает за опрос экспортера Puppet и предоставление данных в формате, который Grafana воспринимает как источник информации. Установка Prometheus сопровождается настройкой конфигурационных файлов, где добавляется задание на сбор данных с локального хоста на стандартном порту экспорта. После запуска и проверки работоспособности доступ к метрикам открывается через веб-интерфейс, позволяя убедиться, что данные поступают корректно. Интеграция с Grafana — следующий критически важный этап, поскольку именно здесь создаются визуальные представления данных.
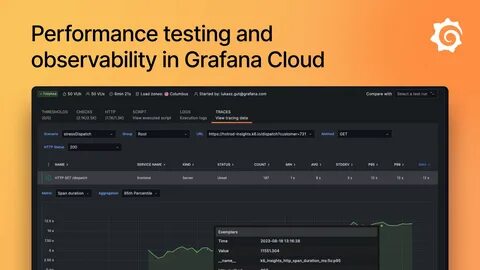
В Grafana настраивается источник данных типа Prometheus с адресом сервера, предоставляющего метрики Puppet. Затем разрабатываются дашборды, отображающие ключевые показатели, такие как длительность выполнения Puppet run, количество изменений ресурсов и отметки времени последних запусков. Благодаря разнообразию возможностей Grafana появляется шанс мониторить динамику, выявлять проблемы и визуально оценивать состояние инфраструктуры. Преимущества подобного подхода очевидны. Во-первых, администраторам становится доступна полная картина работы Puppet без необходимости глубокого изучения внутренних логов.
Во-вторых, появляется возможность автоматизированного выявления аномалий и оповещений о сбоях или нерегулярностях. Также решение помогает анализировать производительность, планировать ресурсы и повышать общую надежность систем. Особое значение имеет масштабирование и кастомизация. В зависимости от размера инфраструктуры, количества узлов и задач, дашборды Grafana можно адаптировать под конкретные нужды бизнеса. Можно выделять отдельные окружения — продакшн, тестовые и стадии разработки, создавать агрегированные отчеты по группам серверов и даже настраивать сложные алерты с уведомлениями в Slack, email или другие системы.
Такая гибкость позволяет обеспечить максимальную отдачу от использования Observability Data Connector в связке с Grafana. Стоит также отметить положительный эффект от объединения метрик Puppet с данными других систем мониторинга, например, с показателями нагрузки на серверы и сетевыми параметрами. Комплексный анализ даёт более глубокое понимание инфраструктуры и открывает дополнительные возможности для оптимизации. Учитывая, что Observability Data Connector — премиум-модуль, доступ к нему регулируется через Puppet Forge, поэтому рекомендуется заранее убедиться в наличии соответствующих лицензий и настройки доступа. Поддержка и обновления модуля идут напрямую от разработчиков Puppet, что гарантирует стабильность и актуальность функционала.
В итоге, интеграция Puppet и Grafana через Observability Data Connector становится мощным инструментом в арсенале современных DevOps-инженеров и системных администраторов. Она позволяет не только повысить прозрачность процессов управления конфигурациями, но и значительно улучшить качество обслуживания инфраструктуры, своевременно выявлять и устранять проблемы, а также принимать обоснованные решения на основе реальных данных. Такой подход оправдывает инвестиции в автоматизацию и визуализацию, превращая рутинный мониторинг в эффективную и стратегически важную функцию работы IT-команды.