В последние годы прогресс в области нейротехнологий и искусственного интеллекта привел к значительным достижениям в понимании того, как человеческий мозг обрабатывает визуальную информацию. Одним из многообещающих направлений является декодирование визуального опыта из сигналов мозга, получаемых с помощью электроэнцефалографии (ЭЭГ). Эта технология, обладая высокой временной разрешающей способностью, позволяет регистрировать мозговую активность в режиме реального времени. Однако недостаточная пространственная детализация ЭЭГ традиционно ограничивала возможности прямого воспроизведения изображений на основе этих сигналов. Новые методы, сочетающие машинное обучение и семантическое моделирование, открывают уникальные пути для интерпретируемого преобразования ЭЭГ в визуальный контент.
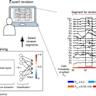
</p> Одним из важных достижений в этой области стало использование мультиизмерных семантических подсказок, представляющих собой описания изображения на разных уровнях абстракции — от конкретных объектов до более широких концепций и тематик. Это кардинально меняет парадигму с прямого восстановления пиксельных изображений на более содержательное и осмысленное сопоставление сигналов ЭЭГ с текстовой семантикой. Чтобы реализовать этот подход, исследователи разработали трансформерный энкодер ЭЭГ, который обучается с помощью контрастного обучения на сопоставлении электроэнцефалографических данных и семантических описаний. После чего, с использованием проекционных моделей, полученные эмбеддинги служат для условного управления предобученной латентной моделью диффузии, способной генерировать изображения высокого качества.</p> Такая текстово-опосредованная рамочная структура позволяет достичь состояния искусства в задаче визуального декодирования на датасете EEGCVPR, одновременно обеспечивая интерпретируемость получаемых результатов за счет соответствия известных нейрокогнитивных путей.
Визуализация внимания модели, включая карты салиентности и проекции t-SNE, демонстрирует семантическое распределение активности по скальпу, что отражает множество уровней восприятия, задействованных в визуальном процессе. Благодаря этому становится возможным исследовать, какие именно семантические аспекты наиболее насыщенно представлены в мозговой активности при просмотре изображений.</p> Использование больших языковых моделей для генерации мультиизмерных семантических описаний стало ключевым элементом инновационной методологии. Такие описания варьируются от простых объектов, как «кошка» или «дерево», до более абстрактных тем, например, «спокойствие», «движение» или «группа людей на улице». Это позволяет модели глубоко учитывать содержание и контекст визуального стимула, что существенно обогащает качество генераций и позволяет понять специфические нейронные подписи, связанные с восприятием различных аспектов.
</p> Важным преимуществом такой модели является ее когнитивная согласованность: построенные связи между электроэнцефалографическими сигналами и семантическими описаниями связаны с известными путями зрительной обработки в мозге. Это открывает перспективы не только для научных исследований, но и для прикладного использования, например, в интерфейсах мозг-компьютер, системах восстановления визуального контента для пациентов с нарушениями зрения или коммуникацией, а также в области креативных технологий и генеративного дизайна.</p> При этом следует отметить, что использование контрастного обучения и трансформерных архитектур обеспечивает высокую адаптивность и масштабируемость модели. Она способна эффективно справляться с шумами, присущими ЭЭГ, и учитывать межиндивидуальные особенности мозговой активности. Кроме того, семантическое посредничество позволяет избежать прямых сопоставлений шумных и плохо структурированных данных ЭЭГ с непосредственно визуальными образами, что всегда было одной из главных проблем в подобных задачах.
</p> Развитие интерпретируемого преобразования ЭЭГ в изображения — это не только технологический прорыв, но и шаг к более глубокому взаимопониманию между человеко-компьютерными интерфейсами и биологическими процессами. Возможности такого подхода лежат в основе новых моделей коммуникации с искусственным интеллектом, где мозговая активность выступает полноценным интерфейсом для создания, поиска и восприятия визуального контента.</p> Научные коллективы и коммерческие компании активно исследуют потенциал этой технологии, стремясь к тому, чтобы в ближайшем будущем появилась возможность не просто фиксировать и хранить визуальные впечатления, но и непосредственно восстанавливать их с помощью умных устройств. Помимо разнообразных практических применений, это также откроет новые горизонты для изучения работы мозга, понимания процессов памяти, восприятия и сознания.</p> В заключение стоит подчеркнуть, что интеграция семантических промптов с ЭЭГ-сигналами открывает пласт возможностей для создания интерпретируемых и высококачественных изображений из данных мозговой активности.
Эта инновационная методика меняет представления об эргономичном и содержательном способе реконструкции визуального опыта и становится новой степенью в эволюции нейротехнологий. Для будущих научных исследований и разработок важно развивать более сложные мультимодальные модели, учитывать индивидуальные нейрофизиологические особенности и расширять понимание взаимодействия между языком, восприятием и когнитивными процессами в мозге.