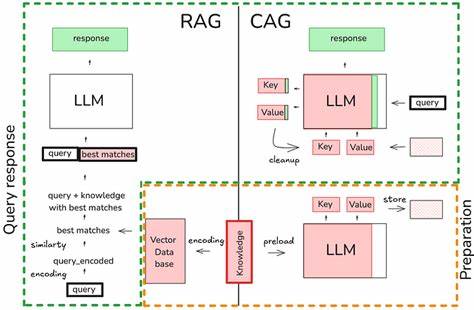
Существует насущная потребность в повышении эффективности обработки больших языковых моделей (LLM), особенно в сферах, где они взаимодействуют с большими объемами контекстуальных данных. Retrieval-Augmented Generation (RAG) — метод, который интегрирует функцию поиска релевантной информации с генеративными возможностями языковых моделей — становится все более популярным. Однако его эффективность во многом зависит от оптимизации работы с кешем ключей и значений (KV Cache), используемым для хранения промежуточного состояния модели. Традиционные методы кеширования имеют свои ограничения, в частности при повторном использовании контекста, что негативно сказывается на скорости и ресурсных затратах. Именно здесь на помощь приходит технология LMCache, которая переосмысливает подход к KV Cache, позволяя реализовать значительный рост производительности, достигая ускорения до 3 раз при работе с RAG.
Основная идея LMCache заключается в возможности переиспользования не-префиксного KV Cache. В отличие от стандартных подходов, где кеш накопляется или обновляется лишь для префикса последовательности, LMCache позволяет перекрывать и объединять кеши из разных частей контекста, которые не обязательно являются началом текста. Это особенно актуально в ситуациях, где контекст меняется динамически: фрагменты могут добавляться, удаляться, перестраиваться, при этом большинство токенов остается неизменным. Благодаря способности «смешивать» кеши соответствующих частей, LMCache существенно сокращает объем вычислений, необходимых для повторной обработки уже использованных данных. Для примера рассмотрим систему, в которой пользователь формирует длинный контекст, выбирая и сортируя отдельные текстовые сегменты.
Такая задача характерна для построения диалогов с учетом различных источников знаний или историй, что свойственно RAG. В условиях стандартного кеша при добавлении нового сегмента или изменении порядка требуется пересчитать KV Cache практически целиком, приводя к замедлению. LMCache же сохраняет кеши отдельных элементов и эффективно комбинирует их по необходимости, обеспечивая мгновенный доступ к уже обработанной информации без повторных затрат на вычисление. Внедрение LMCache предусматривает использование усовершенствованного программного обеспечения, совместимого с современными фреймворками для работы с LLM, такими как vLLM. В практической реализации данный метод поддерживается на уровне серверных backend-систем и демонстрируется специальным демо проектом, в котором сравниваются модели с LMCache и без него в режиме реального времени посредством удобного чат-интерфейса.
Работа такого демо позволяет не только оценить разницу в скорости ответов, но и увидеть качество генерации текста при оптимизированном работе кеша. Для запуска подобного решения потребуется соответствующее оборудование — например, наличие двух графических процессоров NVIDIA для параллельного обслуживания двух версий моделей — и программная инфраструктура, включающая Docker, Python 3.11 и Hugging Face Token для аутентификации с модельными репозиториями. После развертывания компонент и настройки переменных окружения пользователь получает гибкий инструмент для формирования контекста и проведения экспериментов с LMCache. Практическое использование LMCache в RAG ведет к нескольким ключевым преимуществам.
Во-первых, сокращается время до первого токена (TTFT), что особенно важно для интерактивных приложений, где задержки ощущаются пользователем. Во-вторых, существенно уменьшается нагрузка на GPU, позволяя обрабатывать больше запросов и экономить вычислительные ресурсы. В-третьих, улучшенный контроль над кешированием повышает стабильность и надежность работы языковых моделей при работе с переменными и объемными контекстами. Помимо указанных достоинств, LMCache предоставляет гибкость при разработке пользовательских интерфейсов. Использование динамически формируемых контекстов и возможность переупорядочивания текстовых блоков способствует созданию более интуитивных и мощных систем взаимодействия с ИИ.
В тандеме с open-source решениями и широким сообществом разработчиков LMCache становится перспективным инструментом для компаний, работающих с приложениями на базе больших языковых моделей. Таким образом, переиспользование не-префиксного KV Cache в рамках технологии LMCache открывает новые горизонты в повышении эффективности RAG. Интеграция этой технологии позволяет многократно ускорить обработку, повысить отзывчивость приложений и снизить аппаратные требования. С учетом стремительного роста востребованности ИИ-решений данный подход заслуживает внимания специалистов, желающих добиться оптимального баланса между производительностью и качеством генеративных моделей. В дальнейшем развитие LMCache будет способствовать появлению еще более инновационных методов кеширования и управления состояниями моделей, а также расширению областей применения RAG.
Для разработчиков и исследователей это возможность создавать конкурентоспособные продукты, которые обеспечивают высокую скорость работы без компромиссов в качестве и точности генерации. Сегодня LMCache выступает в роли одного из тех технологических прорывов, которые формируют будущее искусственного интеллекта и делают его доступнее для бизнеса и пользователей по всему миру.