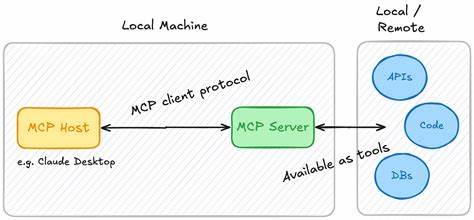
Обучение больших языковых моделей (LLM) – одна из самых мощных и дорогостоящих задач в современной области искусственного интеллекта. Несмотря на постоянные инновации и появление новых технологий, таких как DeepSeek, требование к огромным вычислительным ресурсам, особенно графическим процессорам (GPU), остается крайне высоким. Это порождает множество вопросов от специалистов и энтузиастов: почему современные решения не позволяют существенно снизить нагрузку на оборудование, и какие фундаментальные причины обусловливают это явление? Чтобы разобраться в этих вопросах, необходимо рассмотреть, что такое LLM и как их обучение организовано. Нейросети типа GPT, BERT и подобных представляют собой архитектуры с многочисленными слоями и миллиардами параметров, которые накапливают информацию из огромных объемов текстовых данных. Обучение таких моделей связано с последовательными итерациями обратного распространения ошибки, оптимизацией весов и вычислением градиентов, что требует интенсивных вычислений и большого объема памяти.
GPU в этом процессе играют критическую роль благодаря своей способности параллельно обрабатывать тысячи операций. Их архитектура идеально подходит для матричных умножений и других базовых элементов нейросетевых вычислений. Но, несмотря на это, с ростом размеров моделей и увеличением объема данных, даже самые мощные GPU зачастую становятся бутылочным горлышком для быстрого и эффективного обучения. DeepSeek, как новая технология, призвана оптимизировать обучение и вниз уменьшить потребность в ресурсах, предлагая алгоритмы и методы, которые ускоряют процессы отбора данных, уменьшают избыточность вычислений и повышают эффективность доступа к информации. Однако на практике многие из этих подходов, хоть и перспективны, не приводят к драматическому снижению необходимости в GPU, и причин этому несколько.
Во-первых, масштабы современных LLM настолько велики, что любые попытки улучшения на уровне алгоритмов сталкиваются с ограничениями в архитектуре аппаратного обеспечения. Каждый параметр и каждая операция требуют хранения и обработки, причем с высокой скоростью и точностью. Даже оптимизация потоков данных и вычислительных графов не в состоянии значительно снизить потребность в масштабных параллельных вычислениях. Во-вторых, технологии, подобные DeepSeek, часто фокусируются на частных аспектах обучения, например на методах выборки данных или сокращении числа итераций. Однако основная нагрузка все равно лежит на базовых операциях матричного умножения и обработке больших тензоров, которые не исчезают и не становятся менее требовательными.
Здесь необходимо помнить, что эффективность алгоритма – одна сторона медали, а физические ограничения системы и потребности модели – другая. В-третьих, современные подходы к обучению LLM включают использование сложных техник, таких как смешанная точность, модельное прерывание или разбиение на шардированные субъединицы, которые помогают балансировать нагрузку, но не отменяют необходимости в мощных GPU. Они скорее минимизируют издержки и ускоряют процессы, чем устраняют потребность в масштабных вычислениях. Стоит учитывать и фактор масштабируемости. Компании и исследовательские центры стремятся создавать все более крупные и сложные модели, чтобы добиться прорывов в понимании и генерации естественного языка.
Это означает, что, хотя отдельные технологии могут повышать эффективность, общий тренд роста объема и сложности моделей диктует возрастающую нагрузку на оборудование. Дополнительно следует упомянуть проблемы с энергоэффективностью и охлаждением, которые сопровождают работу массивов GPU в дата-центрах. Оптимизация на уровне алгоритмов не избавляет от необходимости физически рассеивать огромное количество тепла и обеспечивать стабильную работу систем при максимальных нагрузках, что также влияет на общую стоимость обучения. Перспективы снижения зависимости от GPU во многом связаны с развитием специализированных аппаратных решений, например тензорных процессоров нового поколения или нейросетевых ускорителей с улучшенной энергоэффективностью и архитектурой. Кроме того, появляются методы распределенного обучения и улучшенные алгоритмы оптимизации, способные более эффективно использовать доступные ресурсы.
Важно подчеркнуть, что вопросы эффективности обучения LLM являются предметом активных исследований. Теоретическое совершенствование моделей и практическая адаптация оборудования идут рука об руку. Пока технология DeepSeek и ей подобные не стали массовыми и инструментально интегрированными решениями, мы будем наблюдать продолжение тренда на высокую загрузку GPU при тренировках крупных языковых моделей. Таким образом, высокая графическая нагрузка при обучении LLM обусловлена не только текущими алгоритмами и методами обработки данных, но и фундаментальными требованиями архитектуры моделей, масштабами самих задач и ограничениями аппаратного обеспечения. Прорыв в этой области потребует комплексного подхода, объединяющего аппаратные инновации, программные улучшения и алгоритмическую оптимизацию.
Но на сегодняшний день GPU остаются незаменимым элементом в инфраструктуре, обеспечивающей возможности для обучения современных больших языковых моделей.