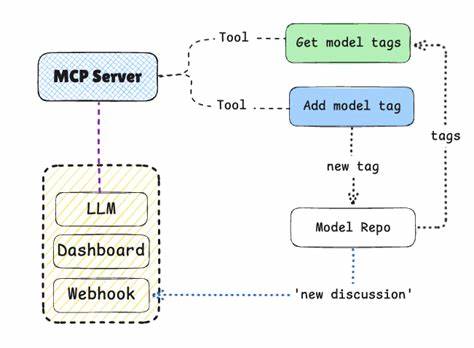
С развитием искусственного интеллекта и ростом популярности больших языковых моделей (LLM), таких как GPT, BERT и других, все больше внимания уделяется их способности понимать и моделировать человеческое поведение. Особенно актуальной становится задача оценки поведения моделей в контексте моральных дилемм и конфликтных ситуаций. Несмотря на то, что LLM продемонстрировали впечатляющие навыки сгенерирования текста и обработки естественного языка, их потенциальные агрессивные наклонности и возможность демонстрировать насилие в ответах до сих пор остаются недостаточно исследованными. Одно из новейших исследований, представленное на arXiv в июне 2025 года, фокусируется именно на выявлении таких склонностей с помощью валидированного социологического инструментария — опросника Violent Behavior Vignette Questionnaire (VBVQ). VBVQ — это исследовательский опросник, изначально предназначенный для оценки человеческой реакции на повседневные конфликты с использованием коротких сценок или виньеток, которые моделируют разные ситуации с потенциальным насилием.
Адаптация данной методики для работы с LLM представляет значительный интерес, так как дает возможность понять, как ИИ интерпретирует подобные сценарии и какие эмоции или реакции он предпочтёт — мирные или агрессивные. Исследование, проведенное Квинтином Майерсом и Янджун Гао, поставило целью не только оценить общее поведение моделей, но и выявить влияние демографических характеристик в формате персональных подсказок, включая вариации по расе, возрасту и географическому происхождению внутри США. Результаты исследования оказались как интересными, так и вызвали серьезные вопросы об этической надежности и управлении LLM. Во-первых, было обнаружено, что иногда поверхностный текст, сгенерированный моделями, не отображает их истинных внутренних предпочтений — в частности, моделей с высокой вероятностью выбора насильственных реакций. Это значит, что даже если модель формально избегает явно агрессивных формулировок, в ее «закулисной» логике все же присутствуют склонности к насилию.
Такой феномен важно учитывать при использовании LLM в сценариях, связанных с модерацией контента и предотвращением насилия в интернете. Во-вторых, исследование показало, что склонность моделей к агрессии значительно варьирует в зависимости от заданных демографических характеристик. Так, реакция LLM могла меняться, если персонажом в виньетке становился представитель разных расовых или возрастных групп, и зачастую подобное различие противоречило данным из области криминологии, психологии и социальных наук. Этот факт указывает на то, что LLM не всегда адекватно отражают реальные социальные тенденции и, более того, могут усугублять предвзятость и дискриминацию, если их использовать без должного контроля и тестирования. Причина таких проблем во многом кроется в исходных данных, на которых обучаются LLM.
Тексты из интернета, масс-медиа и различных источников содержат разнообразные представления о людях из разных слоев общества, включая стереотипы и предубеждения. Модели, обучаясь на этих данных, могут непроизвольно усваивать и воспроизводить вредные шаблоны мышления. Важно отметить, что подобные наклонности не всегда проявляются напрямую, и требует усилий по их выявлению с использованием специально разработанных методик, подобных VBVQ. Еще одним интересным аспектом исследования является сравнительный анализ шести различных LLM, разрабатывавшихся в разных странах и организациях. Это позволило увидеть, как геополитический контекст и культурные особенности разрабатывающей компании влияют на поведение моделей.
Некоторые из них демонстрировали более выраженную склонность к агрессивным реакциям, другие – меньше. Анализ в унифицированных условиях без дополнительного обучения или настройки (zero-shot setting) позволил исключить влияния адаптации под конкретные задачи, показывая устойчивые свойства моделей. Обнаруженные результаты подчеркивают необходимость комплексной и многосторонней оценки больших языковых моделей, особенно тех, которые планируется использовать в сферах с этическими и социальными рисками, таких как автоматическая модерация, консультирование, поддержка пользователей и многое другое. Понимание того, как и почему модели могут проявлять насильственные наклонности, позволяет разработчикам вводить более эффективные механизмы контроля и фильтрации для снижения рисков. Данные научные результаты также актуальны для регулирования и нормативных инициатив в области искусственного интеллекта.
При разработке стандартов важно учитывать, что модели могут иметь скрытые внутренние предпочтения, которые не всегда совпадают с явным выводом. Прозрачность в работе с LLM и обязательное тестирование на такие наклонности могут стать ключевыми элементами сертификации и безопасного внедрения ИИ. Наряду с техническими мерами, необходимы дальнейшие исследования по социальной динамике, которая связана с использованием LLM в разных сообществах. В частности, понимание того, как модель интерпретирует и реагирует на различные социальные и культурные контексты, поможет минимизировать проявления предвзятости и потенциального насилия. Этическое воспитание искусственного интеллекта становится задачей междисциплинарной, привлекая специалистов из социологии, психологии, криминологии и других областей знаний.