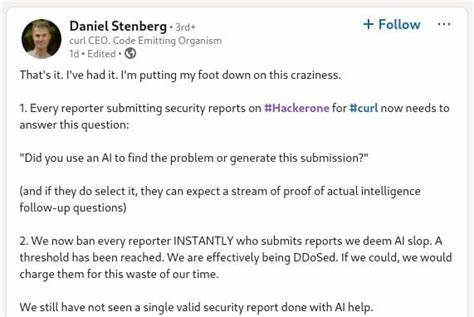
Проект curl является одним из самых популярных и широко используемых инструментов для передачи данных по различным сетевым протоколам. На протяжении многих лет curl завоевал доверие благодаря своей надежности, гибкости и активному сообществу разработчиков. Однако с ростом популярности и повсеместным использованием возрастает и количество сообщений о потенциальных уязвимостях, которые поступают как от профессиональных специалистов по безопасности, так и от автоматизированных систем, основанных на технологиях искусственного интеллекта. В последние годы наблюдается существенный рост количества так называемых AI slop — сгенерированных отчетов о безопасности, которые зачастую содержат непроверенную, неточную или искусственно созданную информацию. Это явление вызывает серьезные опасения в сообществе curl и среди профессионалов, ответственных за безопасность продукта.
Основная сложность AI slop заключается в том, что такие отчеты часто выглядят правдоподобно на первый взгляд, содержат типичные для уязвимостей термины и описания, что затрудняет их оперативную проверку и фильтрацию. В curl действует четкая политика: все сообщения и отчеты о безопасности зверяются через официальную программу bug-bounty на платформе HackerOne, где специалисты проводят тщательный анализ. Однако массовые случаи AI-сгенерированных отчетов приводят к загромождению системы, задержкам в выявлении реально опасных уязвимостей и дополнительным нагрузкам на разработчиков. Несмотря на негативный контекст, нельзя отрицать, что автоматизация и искусственный интеллект обладают огромным потенциалом для повышения эффективности поиска уязвимостей, если их использовать грамотно. Проблема заключается в недоработанности технологий генерации отчетов и недостаточной фильтрации ложных срабатываний.
Некоторые AI-модели создают отчёты, имитирующие реальные баги с ошибками переполнения буфера, форматных строк, уязвимостей в обработке протоколов, включая HTTP/2, HTTP/3 и MQTT, что вызывает ложные тревоги. Различные известные случаи из истории curl включают критические уязвимости, например CVE-2023-38545, которые действительно требовали быстрого реагирования и исправления. Вместе с тем, растущая лавина сообщений с преувеличенной или недостоверной информацией осложняет работу над реальными проблемами. В числе обнаруженных уязвимостей были случаи переполнения буфера в функциях strcpy, ошибки управления памятью, проблемы с обходом протокольных ограничений, использование устаревших или небезопасных криптографических алгоритмов, уязвимости в работе с HTTP Proxy, техники атаки HTTP Request Smuggling и многие другие. Каждый такой отчет требует внимательного рассмотрения в контексте реальности и воспроизводимости.
Важное направление дальнейшего развития безопасности curl — повышение фильтрации поступающих отчетов, снижение количества ложных срабатываний и забота об интеллектуальном анализе данных. Хорошей практикой является интеграция методов машинного обучения для предварительного скрининга сообщений и выделения риска, но при этом необходимо сохранять человеческий контроль и экспертизу как ключевой элемент процесса. Сообщество curl всегда остается открытым для реальных сообщений о проблемах, будь то от профессионалов безопасности, сами разработчики или заинтересованные пользователи, однако резкое снижение доверия к частым необоснованным сообщениям AI slop требует адекватных политик и технических решений. Проблематика AI slop подчеркнула важность создания и поддержания надежных каналов коммуникации и отчетности, которые бы способствовали быстрой и точной передаче сведений о безопасности. Исторически, curl успешно реагировал на важные отчеты и устранял найденные проблемы, что является залогом его высокой надежности и широкого применения в индустрии.
Однако вызовы, связанные с ростом автоматизированного шума, показывают необходимость развития новых механизмов контроля и модерации. В дополнение к техническим аспектам, данный феномен затрагивает и психологический фактор профессионального сообщества. Возникает усталость от постоянной проверки ложных срабатываний, что может отвлекать от действительно критичных уязвимостей и замедлять реакцию. Это обстоятельство требует возрождения уважения к качественным сообщениям и повышения дисциплины среди репортеров, особенно тех, кто использует современные AI-инструменты для поиска уязвимостей. Для разработчиков curl и других крупных проектов становится приоритетом совместная работа над совершенствованием процесса обработки уязвимостей.
Внедрение специализированных фильтров, интеллектуальных систем ранжирования, расширение ролевой ответственности и взаимодействие с экспертным сообществом призваны минимизировать влияние AI slop и повысить защиту конечных пользователей. Такой комплексный подход позволит сохранить доверие к проекту и обеспечить безопасность на высоком уровне. Итогом является понимание, что технологии искусственного интеллекта сами по себе не являются угрозой безопасности, а их применение без достаточной фильтрации и контроля — источник проблем. Отсюда следует необходимость внедрения сбалансированных стратегий, которые объединяют автоматические решения и компетенции специалистов. Лишь такой подход обеспечит эффективное выявление и устранение реальных уязвимостей и защиту сложных инфраструктур, базирующихся на curl.
Таким образом, вызовы, связанные с AI slop отчетами о безопасности curl, иллюстрируют более широкую тенденцию современного киберпространства – рост объема данных и необходимость качественного анализа с использованием передовых технологий. Путь к обеспечению безопасности лежит через умение фильтровать, интегрировать новые методы и сохранять человеческий фактор. Только так можно гарантировать, что curl останется надежным и безопасным инструментом, выдерживающим испытание временем и современными угрозами.