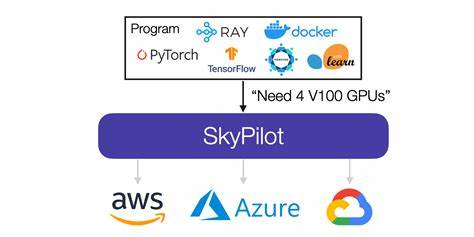
В современном мире машинного обучения и искусственного интеллекта высокопроизводительные вычисления на GPU стали ключевым инструментом для создания и обучения масштабных моделей, таких как большие языковые модели. Однако, чтобы добиться максимальной эффективности, недостаточно просто иметь мощные графические процессоры. Ключевую роль в распределённых вычислениях играет правильно настроенная сетевая инфраструктура, способная обеспечить быструю и надежную передачу данных между узлами. На практике настройка такой сетевой инфраструктуры в разных облачных средах представляет серьезную задачу из-за разнообразия платформ, их специфики и особенностей реализации. SkyPilot пришел на помощь, автоматизировав этот сложный процесс и значительно упрощая работу специалистов, работающих с кластерными вычислениями.
Сетевые особенности облачных платформ и сложности настройки Каждый облачный провайдер предлагает свой уникальный стек сетевых решений, что отражается и на производительности распределённых вычислительных задач. Например, у Google Cloud Platform (GCP) используются технологии вроде GPUDirect-TCPX и GPUDirect-RDMA для разных серий инстансов с Nvidia GPU. На Nebius применяются InfiniBand-соединения с MLX5 адаптерами и оптимизациями UCX, которые обеспечивают минимальную задержку и высокую пропускную способность для обмена данными. Усложняет ситуацию использование управляемых Kubernetes-сервисов, таких как GKE (Google Kubernetes Engine) и Nebius Managed Kubernetes. Здесь добавляется слой оркестрации контейнеров, сложности с конфигурацией pod-сетей, интеграцией GPU device plugins, а также дополнительными параметрами, влияющими на производительность.
Каждая из этих систем требует особого подхода и точной настройки, иначе можно столкнуться с резким падением эффективности работы. Ручная установка и настройка таких сетей — кропотливый и долгий процесс, требующий глубоких знаний сетевой архитектуры каждой платформы, постоянного отслеживания обновлений и изменений, а также ряда последовательных шагов по установке драйверов, конфигурации сетевых интерфейсов и многого другого. Ошибки в настройке приводят не только к потере времени, но и к значительному увеличению расходов на аренду дорогостоящих GPU-инстансов, так как процесс отладки может затянуться на дни. SkyPilot и решение проблемы сетевого хаоса SkyPilot разработал уникальный подход к автоматизации сетевой настройки на GPU-кластерах, перекрывая всю эту сложность уровнем абстракции — network tier. С помощью простой декларативной конфигурации в файле skypilot.
yaml, пользователи могут указать требуемый уровень сетевой производительности, и система самостоятельно подберёт оптимальные инстансы и настроит всю сетевую инфраструктуру, включая GPU-связь и интеграцию с Kubernetes, если это необходимо. Это позволяет сконцентрироваться непосредственно на разработке и обучении моделей, а не тратить время на изучение тонкостей специфики каждой облачной платформы. SkyPilot берет на себя задачи по установке необходимых драйверов, настройке среды и запуску проверочных тестов для обеспечения оптимальной производительности посредством автоматического управления всеми нюансами сетевого взаимодействия. Повышение производительности и снижение затрат В ходе тестов SkyPilot продемонстрировал значительные преимущества по сравнению с обычными способами настройки. NCCL (NVIDIA Collective Communications Library) тестирование показало до 3,8-кратного ускорения передачи данных для крупных сообщений, что критично для эффективного обучения распределённых моделей.
Для задач сервисинга больших языковых моделей было зафиксировано увеличение пропускной способности более чем на 11% и снижение задержек почти на 8%, что напрямую улучшает качество и скорость отклика моделей в реальном времени. Эффективность автоматизированного подхода SkyPilot напрямую отражается на снижении операционных расходов. Устранение необходимости ручной отладки сетевых настроек и их унификация сократили время запуска кластеров с нескольких дней до нескольких минут. Это особенно актуально при использовании дорогих GPU-ресурсов, где каждая минута простаивания — это прямые финансовые потери. Поддержка различных облаков и будущие перспективы SkyPilot не ограничивается только Google Cloud и Nebius.
Платформа расширяет поддержку других крупных облаков и инфраструктур с уникальными сетевыми стеками, такими как AWS с технологиями EFA и HyperPod, Microsoft Azure с InfiniBand, Oracle Cloud с RoCE, а также специализированные сервисы Lambda Labs, CoreWeave и RunPod. Это позволяет пользователям гибко выбирать оптимальное соотношение цена/качество и инфраструктуру без боязни потерять в производительности. В будущем SkyPilot планирует продолжать улучшать алгоритмы определения и автоматической настройки сетевых уровней, повышать совместимость с новыми версиями Kubernetes и GPU-драйверов, а также расширять возможности по интеграции с сервисами мониторинга и автоматического масштабирования. Это сделает платформу ещё более универсальной и удобной для широкого спектра задач от исследований до коммерческих проектов. Заключение Автоматизация сетевой настройки GPU-кластеров на разных облаках — ключевой шаг для продвижения масштабируемых и высокопроизводительных машинных обучающих систем.
SkyPilot предлагает уникальное решение, которое устраняет сложности, связанные с множеством платформ и их особенностей, гарантируя пользователю максимальную производительность и минимальные издержки на управление. Это увеличивает скорость вывода проектов на рынок и позволяет сосредоточиться на самом важном — создании инновационных моделей искусственного интеллекта. Для специалистов и команд, работающих с распределёнными вычислениями и большими моделями, SkyPilot становится надёжным помощником и инструментом, упрощающим взаимодействие с облачной инфраструктурой. Переходите к автоматизированному управлению сетями и дайте вашему ML-кластеру раскрыть весь свой потенциал с SkyPilot.