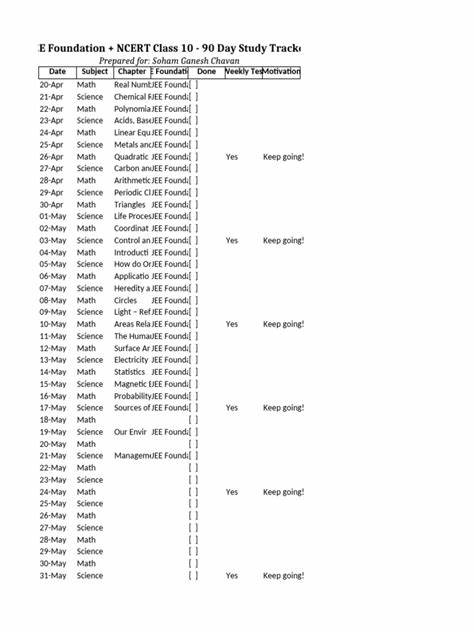
![Rethinking Data Use in Large Language Models (2024)[pdf]](/images/9ADC42EF-F554-4227-ABCF-4A85DC38A34F)
В последние годы большие языковые модели (БЯМ) стали неотъемлемой частью современных технологий искусственного интеллекта, влияя на бизнес-процессы, коммуникацию и обработку информации. В 2024 году тема переосмысления подходов к использованию данных для обучения таких моделей приобретает особую актуальность ввиду растущих требований к качеству, этичности и эффективности. Особенно важной становится диссертация Севона Мина, представленная в Университете Вашингтона, которая ставит новые ориентиры в понимании ролей данных в развитии БЯМ и предлагает системные решения на основании глубокого академического исследования. В этом материале мы рассмотрим ключевые идеи и новации, выделенные в работе, а также почему именно сейчас необходимо переосмысление традиционных практик обработки и управления информацией при обучении больших языковых моделей. Большие языковые модели являются сложными системами, которые требуют обширных объемов данных для своего обучения.
Традиционно модели обучаются на миллиардах текстовых фрагментов, собранных из интернета, книг, статей и других источников. Однако не все данные одинаково полезны и безопасны для формирования интеллектуальных алгоритмов. Один из новых трендов в 2024 году связан с качеством данных, а не просто с их количеством. Севон Мин в своей диссертации подчеркивает важность тщательного отбора информации, что ведет к снижению шума, уменьшению вредного контента и повышению релевантности обучающих примеров. Такой подход улучшает не только точность моделей, но и их способность к пониманию контекстов и многозначностей, что особенно ценно в применении для реальных задач от обработки запросов пользователей до генерации синтетических текстов.
Этические аспекты использования данных в БЯМ занимают одно из центральных мест в обсуждении. В 2024 году растут опасения касательно приватности и легитимности источников информации. Диссертация акцентирует внимание на необходимости создания прозрачных процессов сбора и валидации данных, чтобы минимизировать риски нарушения авторских прав и утечки личной информации. Это способствует формированию доверия пользователей и общественности к технологиям искусственного интеллекта, что является фундаментом для их широкого внедрения. Вместе с этим технологические инновации позволили разработчикам более эффективно управлять наборами данных.
Новые методы фильтрации, автоматического аннотирования и балансировки учебных примеров позволяют придать моделям более устойчивое понимание языка и контекстов. В работе Севона Мина подробно описываются алгоритмы, которые не только увеличивают производительность моделей, но и способствуют их адаптивности — способности быстро перенастраиваться на новые типы данных или задачи без необходимости полного переобучения. Помимо этого, важным моментом является масштабируемость новой парадигмы использования данных. Традиционные подходы становились затруднительными при увеличении объема информации и усложнении моделей. Предложенные инновационные решения ориентированы на эффективное использование вычислительных ресурсов, что ведет к снижению затрат и увеличению скорости обучения.
Это открывает перспективы для создания более экологичных и доступных моделей, способных работать даже в условиях ограниченной инфраструктуры. Особое внимание уделяется также междисциплинарным аспектам работы с данными. БЯМ не просто обрабатывают текст, они становятся инструментом, интегрированным в различные сферы человеческой деятельности. В 2024 году отмечается активное использование моделей в медицине, образовании, юридической практике и других областях, где правильное понимание и этичное использование данных критически важно. Представленная диссертация способствует развитию стратегий, которые учитывают эти особенности и позволяют создавать более универсальные и надежные инструменты.
В завершение стоит отметить, что переосмысление данных в контексте больших языковых моделей — это тенденция, которая будет только набирать обороты. Работа Севона Мина задает стандарты и направления, в которых развитие искусственного интеллекта будет идти как с технологической стороны, так и с позиций ответственности перед обществом. Текущие инновации формируют фундамент для создания будущих решений, где данные будут не просто сырьём, а интеллектуальным ресурсом, управляемым с максимальной точностью, этичностью и эффективностью. Рынок и научное сообщество внимательно следят за развитием в этой области, понимая, что именно от правильного использования данных зависит дальнейший прогресс и интеграция искусственного интеллекта в повседневную жизнь человека.