С развитием искусственного интеллекта и особенно языковых моделей наблюдается стремительный рост спроса на их инференс — процесс генерации ответов и выполнения вычислений в режиме реального времени. Компании, занимающиеся разработкой и предоставлением сервисов на базе больших языковых моделей (LLM), сталкиваются с необходимостью находить баланс между быстрой обработкой запросов и экономически оправданным использованием вычислительных ресурсов. В последние годы наблюдается тенденция к увеличению доходов от инференса в отрасли примерно в три раза в год, несмотря на то, что модели становятся компактнее и дешевле по сравнению с 2023 годом. Это указывает на растущую востребованность скорой и качественной работы алгоритмов при все более сложных задачах и более длительных диалогах с пользователем. Раньше для оценки «достаточной» скорости генерации модели ориентировались на человеческую скорость чтения — если модель могла выдавать порядка десяти токенов в секунду, ее считали достаточно быстрой.
Однако по мере усложнения выводов и интеграции ИИ в агентные системы подобный подход становится недостаточным, так как более быстрая генерация открывает новые возможности взаимодействия и улучшает пользовательский опыт. Несмотря на эту необходимость, до недавнего времени недоставало исследований, фокусирующихся на том, как эффективно увеличить скорость инференса и разобраться в экономике этого процесса — во сколько обойдется ускорение и где находятся технологические ограничения. Для решения этой задачи была представлена новая модель экономики инференса языковых моделей, которая разбирает составляющие время вычислений и позволяет оптимизировать параметры сервиса с точки зрения затрат и времени отклика. Главная идея модели — декомпозиция общего времени выполнения прямого прохода через трансформер на несколько ключевых компонентов. В первую очередь следует выделить арифметическое время — это время работы ядер графического процессора над операциями сложения и умножения, необходимых для вычисления новых значений в нейросети.
Второй важный фактор — время чтения и записи данных из оперативной памяти с высокой пропускной способностью (HBM), обеспечивающей высокоскоростной обмен информацией с ядрами. Третий компонент связан с сетевым взаимодействием — временем передачи данных между GPU в распределенных вычислениях, зависимым от пропускной способности сети приема. Наконец, четвертый элемент — фиксированная латентность, то есть задержки, возникающие при запуске ядра, синхронизации работы нескольких GPU и вызовах библиотек низкого уровня (например, NCCL на системах с NVIDIA DGX H100). Для точного подсчета время на выполнение вперед-пропуска через модель учитывает возможность частичного наложения этих этапов, поскольку, например, операции чтения памяти могут выполняться параллельно с арифметическими вычислениями. Далее с помощью перебора всех доступных конфигураций запуска инференса можно получить оптимальные значения параметров, которые минимизируют стоимость при заданной скорости или максимизируют скорость при фиксированных затратах.
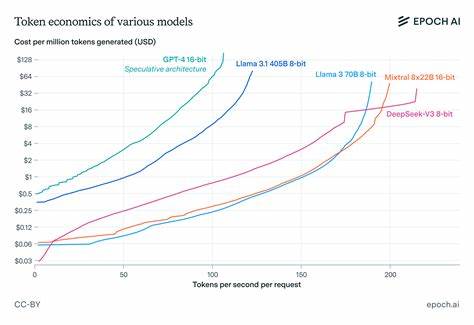
Таким образом формируется эффективная линия фронта (Pareto frontier) для сервиса инференса. Одним из главных результатов исследования стала оценка важности сетевой латентности. Несмотря на то, что часто обсуждается пропускная способность сети, в реальности при работе с небольшими батчами токенов в инференсе узким местом оказывается именно задержка передачи данных, особенно при масштабировании по числу GPU. Если бы сетевые задержки отсутствовали, можно было бы существенно ускорять инференс за счет распараллеливания расчетов — фактически увеличивая скорость в четыре раза при удвоении затрат на обработку каждого токена. Однако на практике именно задержки не позволяют добиться таких значительных приростов.
Масштабирование скорости генерации токенов для плотных трансформеров подчиняется ориентировочным законом: скорость обратно пропорциональна квадратному корню из числа параметров модели и пропорциональна кубическому корню из пропускной способности памяти. Эти эмпирические зависимости подтверждаются простой теоретической моделью и хорошо согласуются с практическими наблюдениями, являясь удобным инструментом для грубой оценки возможных улучшений. Еще одна рекомендация касается выбора стратегий распараллеливания. Pipeline-параллелизм, при котором модель делится на этапы, распределяемые по разным GPU, оправдан лишь тогда, когда требуется разместить очень большую модель, превышающую объем доступной памяти одного GPU. В противном случае зачастую выгоднее использовать data-параллелизм, при котором полноразмерная модель копируется на несколько устройств, а батчи делятся между ними.
Это связано с тем, что pipeline требует сокращать батчи, чтобы загрузить все этапы расчетов без простаивания, и сопряжено с дополнительными коммуникационными затратами между этапами. Следовательно, если скорость вывода токенов превышает время, необходимое для прочтения содержимого памяти одного GPU, pipeline-параллелизм становится невыгодным. Для современных GPU, таких как NVIDIA H100, это примерно 42 токена в секунду — если инференс работает быстрее, pipeline не следует применять. Особая роль отводится методам спекулятивного декодирования. Эти техники позволяют одновременно генерировать несколько токенов за один проход через модель, уменьшая влияние латентности сети и пропускной способности памяти на итоговую скорость.
В результате использование спекулятивного декодирования в больших моделях может удвоить скорость генерации токенов без роста затрат или ухудшения качества ответов. В противоположность этому арифметические затраты и пропускная способность сети при таком подходе не изменяются, но благодаря амортизации времени по нескольким токенам возникает заметный выигрыш. В целом, экономика инференса языковых моделей является сложной, но важной областью, критической для развития прикладных решений на базе ИИ. Непонимание реальных ограничений и масштабируемости ведет к ошибочным решениям и переоценке возможностей. Представленная модель открывает прозрачность в процессах, позволяя лучше понять компромиссы между скоростью и стоимостью, и помогает разрабатывать более эффективные технические архитектуры и бизнес-стратегии.
По мере роста потребностей в более быстрых и комплексных выводах от ИИ, экономика инференса станет ключевым фактором для компаний, стремящихся обеспечить качественный пользовательский опыт и рентабельность своих сервисов. Новые разработки в области аппаратного обеспечения, сетевых протоколов и алгоритмов оптимизации будут иметь решающее значение для дальнейшего прогресса. Эксперты и исследователи в области ИИ рекомендуют комплексный подход, учитывающий аппаратные ресурсы, программное обеспечение и экономику для достижения оптимальной производительности. Таким образом, исследование экономики инференса языковых моделей — это неотъемлемый этап на пути к масштабированию ИИ и его успешной интеграции в повседневные технологии и бизнес-процессы.