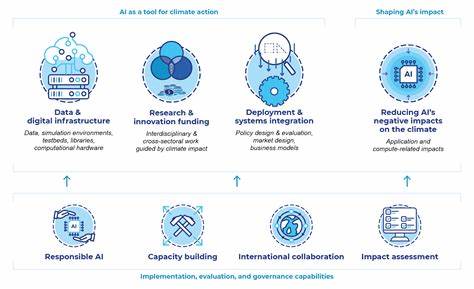
В современном мире данных становится все больше, и вопрос о том, как мы можем извлечь из них полезную информацию, становится все более актуальным. Каждый день мы генерируем терабайты информации: от социальных сетей и банковских транзакций до медицинских записей и данных о погоде. Но где же находится эта информация, и как мы можем ее эффективно использовать? Новый подход, называемый "Распределенный информационный бутылок" (Distributed Information Bottleneck или DIB), предлагает свежий взгляд на эту проблему. Распределенный информационный бутылок представляет собой концепцию, которая фокусируется на том, как различные характеристики данных могут быть использованы для создания предсказательных моделей. Это похоже на задачку по сбору пазла: каждый элемент (или характеристика) приносит свою уникальную ценность и, когда они объединяются, создают целостное изображение.
Чтобы понять, как работает DIB, важно осознать, что каждая характеристика данных за собой несет информацию. Например, если рассматривать данные о пациентах в больнице, такие как возраст, пол и история болезни, каждая из этих характеристик содержит некую информацию, которую можно использовать для прогнозирования здоровья пациента. Распределенный информационный бутылок позволяет выделить наиболее информативные характеристики данных, а также важные отличия внутри каждой из них, для достижения оптимальной предсказательной точности. Традиционно в машинном обучении акцент делается на достижении максимальной производительности модели на определенной метрике. Однако подход DIB меняет эту парадигму.
Вместо того чтобы лишь стремиться к высокой точности, DIB акцентирует внимание на самом процессе обучения, причинно-следственных связях и информации, которая может быть "потеряна" в процессе. Результатом обучения с использованием DIB становится не просто модель, но и карта, указывающая, где находится информация в данных. Как же это работает на практике? Основной компонент DIB — это вероятностный энкодер для каждой характеристики данных и так называемая "наказание" Кулбака-Лейблера (KL divergence), значение которого постепенно увеличивается в процессе обучения. Это позволяет поэтапно сжимать информацию, определяя, какие именно аспекты данных являются наиболее значимыми. В результате мы получаем простую, но мощную модель, способную обрабатывать разнообразные формы данных, включая табличные данные, временные ряды и изображения.
Эта модель называется DistributedIBNet и реализована в популярной библиотеке TensorFlow, что делает ее доступной для широкого круга исследователей и практиков. Использование этой модели ни в чем не ограничивает привычные методы работы с машинным обучением. Вы можете применять стандартные методы, такие как model.compile(..
.) и model.fit(...
), но при этом получите дополнительные возможности. Применение DIB находит все большее признание в научных исследованиях и практике. Например, при анализе материалов, таких как стеклянные вещества, можно использовать DIB для идентификации очень узких характеристик, которые способны повлиять на свойства и поведение этих материалов. Это разнообразие применения делает DIB универсальным инструментом, способным адаптироваться к различным областям исследования. Для исследователей и специалистов DIB не только инструмент, но и методология для глубокого понимания информации в своих данных.
Он позволяет не только работать с большими объемами информации, но и извлекать из них полезные инсайты. Повышение информативности и объяснимости моделей — это то, что делает их более надежными и понятными для пользователей. Одним из важных аспектов DIB является его способность справляться с большим числом характеристик данных. В традиционных подходах часто возникает проблема "проклятия размерности", когда увеличение числа характеристик приводит к ухудшению общей производительности модели. Однако DIB уменьшается за счет сосредоточения на июльних характеристиках, а не на количестве.
Это позволяет исследователям лучше понимать, какие именно данные действительно имеют значение и как они взаимодействуют между собой. Тем не менее, как любой новый метод, DIB не лишен своих недостатков. Для его эффективного применения требуется глубокое понимание структуры данных и характера задачи. Кроме того, возможны случаи, когда полезность определенных характеристик может быть недооценена, что приводит к упущенным возможностям. Поэтому очень важно постоянно оценивать и сравнивать результаты, полученные с использованием DIB, с другими существующими методами.
Среди будущих направлений работы с DIB стоит отметить его интеграцию с другими методами машинного обучения, такими как глубокие нейронные сети и генетические алгоритмы. С учетом возможностей и гибкости DIB, можно ожидать новых прорывов и инноваций в области анализа данных и предсказательной аналитики. Таким образом, понимание того, где находится информация в ваших данных, становится ключом к успешному применению современных технологий. Подходы, такие как распределенный информационный бутылок, открывают новые горизонты в анализе данных, позволяя нам не только извлекать информацию, но и лучше понимать нашу окружающую среду. Когда речь идет о большом количестве данных, важно не просто их собирать, но и уметь извлекать ценную информацию, которая может быть использована для принятия более обоснованных решений.
В условиях быстроменяющегося мира, где данные становятся все более важным ресурсом, навыки работы с ними станут определяющими для успеха в любой области.