В последние годы большие языковые модели (LLM) достигли впечатляющих успехов в самых различных областях — от генерации текста до решения комплексных задач, требующих многократных шагов рассуждений. Однако при всех своих возможностях эти модели порождают новые вызовы, особенно связанные с пониманием и интерпретацией их внутреннего процесса мышления. Рассмотрение каждого сгенерированного токена или шага как зависимого от всех предыдущих усложняет анализ и делает трудно понять, какие конкретно части рассуждений действительно влияют на итоговый ответ. Новое направление исследований в этой области связано с выявлением так называемых «thought anchors» или «якорей мысли» — ключевых этапов рассуждений, обладающих несоразмерно большим влиянием на дальнейший ход мышления модели. Несмотря на многоуровневую и цепочечную структуру творимого текста, обнаруживается, что не все предложенные моделью шаги одинаково значимы.
Часто именно отдельные предложения или фразы выполняют роль стратегических узлов, определяющих траекторию и качество рассуждений. Идея изучать модель на уровне отдельных предложений, а не токенов или символов, стала основой нового подхода к интерпретации работы LLM. Предложены несколько методик, благодаря которым можно определить весомость конкретных предложений в цепочке рассуждений. Первая из них — черный ящик, базирующийся на контрфактическом анализе. Она заключается в проведении большого количества повторных прогонов модели, где в одном случае модель формирует конкретное предложение, а в другом оно заменяется на альтернативное с измененным смыслом.
Сравнивая результаты, можно выявить насколько критично именно это предложение для итогового вывода. Такой подход эффективно демонстрирует, как вмешательство в отдельный элемент текста может повлиять на конечный ответ. Вторая методика — «белый ящик», которая опирается на анализ внутренних параметров модели, а именно паттернов внимания (attention) между предложениями. Применяя ее, исследователи выявили явление «широковещательных» предложений — таких, которые получают непропорционально много внимания со стороны последующих высказываний через специальные «приемные» attention-хэды в модели. Это указывает на то, что модель отличает ключевые элементы рассуждений, распространяя знания, полученные на их основе, по всей цепочке.
Третий метод базируется на причинной атрибуции и предусматривает подавление внимания модели к определенному предложению с последующим наблюдением влияния данного действия на генерацию будущих токенов. Такой подход помогает не просто локализовать важный этап, но и понять его логическую связь с последующими шагами рассуждения. Объединение результатов этих трех методов дает убедительные доказательства существования thought anchors и их центральной роли в многошаговом мышлении больших языковых моделей. В частности, исследователи установили, что такие якоря часто связаны с планированием процесса рассуждения или с этапами проверки и корректировки ранее сделанных выводов — бэктрекингом. Понимание того, какие именно части цепочки рассуждений модели оказываются наиболее значимыми, открывает новые перспективы для разработки более прозрачных и надежных систем искусственного интеллекта.
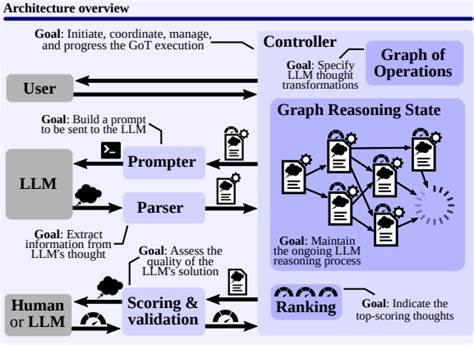
С одной стороны, это облегчает диагностику ошибок и улучшение качества ответов, а с другой — повышает доверие к работе моделей за счет возможности объяснения причин тех или иных выводов. Важной составляющей исследований стало создание открытых инструментов визуализации, позволяющих наглядно наблюдать за тем, как именно модель строит рассуждения, какие предложения оказывают наибольшее влияние и как они взаимосвязаны. Такие визуализации позволяют исследователям и разработчикам погружаться в механизм работы LLM на уровне интерактивных диаграмм и графов, что существенно расширяет доступные методы анализа. Подобные методики и подходы по сути приближают большие языковые модели к тому, чтобы стать не просто генераторами текста, а настоящими мыслительными механизмами с понятной и объяснимой структурой мышления. Это ключевой шаг к более широкой интеграции и применению LLM в критичных областях, таких как медицина, право, образовательные технологии и другие сферы, где крайне важна прозрачность принимаемых решений и их обоснованность.
В долгосрочной перспективе исследование thought anchors может помочь в создании моделей, которые не только эффективно решают задачи на языке, но и ведут себя как истинные партнеры в рассуждениях, демонстрируя способность к самоанализу, планированию и коррекции своих действий. Это открывает путь к созданию комплексного искусственного интеллекта, максимально приближенного к человеческому мышлению как по структуре, так и по качеству исполнения. Таким образом, фокус на ключевых этапах рассуждений LLM — thought anchors — это не просто научная абстракция, а практическое направление, обладающее потенциалом существенно повысить эффективность, надежность и прозрачность современных языковых моделей. В связи с этим дальнейшие исследования в этой области будут играть важнейшую роль в развитии технологий искусственного интеллекта, способных качественно взаимодействовать с людьми и обрабатывать сложные интеллектуальные задачи.