В эпоху цифровизации и растущих объемов данных роль инженера данных становится все более ключевой в обеспечении стабильной и эффективной работы компаний. Современный инженер данных — это архитектор целой экосистемы, который не только занимается обработкой и анализом данных, но и строит масштабируемую инфраструктуру, внедряет современные практики DevOps, а также использует искусственный интеллект для оптимизации рабочих процессов. Разбор инструментов, технологий и навыков, которыми должен владеть современный Data Engineer, позволяет понять, как именно строятся и сопровождаются системы обработки данных — от базовых до продвинутых этапов. SQL и базы данных остаются фундаментом в арсенале любого инженера данных. Несмотря на развитие новых технологий, умение грамотно работать с языком SQL востребовано практическим всегда.
Именно SQL лежит в основе взаимодействия с реляционными базами данных, обеспечивающими хранение и быстрый доступ к разнообразной информации. Популярные OLTP-системы, такие как PostgreSQL, MySQL и SQLite, являются неотъемлемой частью повседневной работы, так же как и OLAP-решения для аналитики — DuckDB, ClickHouse, Snowflake и облачные дата-склады на базе BigQuery, Redshift и Azure Fabric. Эти системы обеспечивают масштабируемость и высокую скорость вычислений, что особенно важно для обработки больших данных. Python уже давно стал универсальным языком для разработки сложных ETL-процессов и автоматизации задач. Его богатая экосистема библиотек позволяет решать широкий спектр задач — от извлечения данных из REST API до параллельных вычислений и построения аналитических моделей.
Библиотеки, такие как Dask, Ibis, Vaex и ConnectorX, помогают справляться с большими объемами данных, распределенными вычислениями и ускоряют загрузку данных из баз. Такая гибкость Python делает его идеальным «клеем» между различными сервисами и инструментами. Оркестрация рабочих процессов — важнейший аспект надежного построения пайплайнов данных. Системы на базе Python, включая Apache Airflow, Dagster и Prefect, помогают организовать сложные зависимости, контролировать расписание задач и обеспечивать мониторинг выполнения. Благодаря таким инструментам инженеры данных могут управлять даже самыми запутанными цепочками обработки данных, что гарантирует целостность и своевременный результат анализа.
Визуализация данных и бизнес-аналитика выступают связующим звеном между техническими специалистами и бизнес-пользователями. Выбор BI-платформ зависит от масштабности проектов и требований к функционалу. Среди наиболее популярных решений — Apache Superset, PowerBI, Tableau и Sigma Computing. Они позволяют быстро создавать понятные отчеты, дашборды и интегрироваться с существующими базами данных, облегчая принятие решений на управленческом уровне. Однако построение надежной data-платформы не обходится без масштабируемой инфраструктуры и современных DevOps-практик.
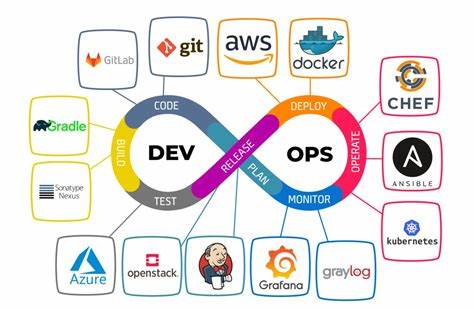
Контейнеризация приложений, управляемая через Docker и Kubernetes, стала стандартом в развертывании и поддержке сложных систем. Kubernetes предоставляет облачную независимость и автоматическое масштабирование ресурсов, что критично для устойчивости производства. Управление инфраструктурой через код с помощью Terraform, Ansible или Pulumi позволяет создавать воспроизводимые среды, минимизировать человеческий фактор и ускорять процессы деплоя. Концепция Infrastructure as Code (IaC) и методологии GitOps сформировали новую культуру взаимодействия между командами разработки и эксплуатации. Хранение конфигураций в git-репозиториях обеспечивает прозрачность, удобство аудита и упрощает откат изменений.
Инструменты, такие как ArgoCD и Flux, позволяют автоматически синхронизировать состояние кластеров с репозиториями, что уменьшает риски ошибок и повышает скорость внедрения обновлений. Важным элементом современной платформы являются решения для обеспечения качества данных и мониторинга состояния системы. Комплексные инструменты, такие как ELK Stack, Prometheus и DataDog, помогают собирать метрики, визуализировать логи и обнаруживать аномалии в работе пайплайнов. Специализированные решения вроде Soda, Datafold и Monte Carlo способны эффективно контролировать целостность и достоверность данных на каждом этапе обработки, минимизируя влияние ошибок на бизнес. Новые горизонты открывает внедрение искусственного интеллекта и автоматизация разработки с помощью AI-усиленных инструментов.
Например, интеграции с LLM (Language Models) позволяют инженерам данных ускорять написание запросов, автоматически тестировать и оптимизировать код. Появление инструментов наподобие nao, которые глубоко понимают dbt-проекты и умеют запускать пайплайны, оптимизируют регулярные задачи и снижают ручной труд. Помимо технических навыков, важное значение приобретает развитие «мягких» компетенций. Умение слушать бизнес-пользователей, формулировать требования и работать в командах с разными функциями становится отличительной чертой успешного инженера данных. Только комбинируя техническую экспертизу с глубоким пониманием бизнес-процессов и эффективной коммуникацией, можно создавать решения, приносящие реальную ценность организации.