В современном мире искусственного интеллекта и обработки естественного языка производительность и эффективность моделей играют решающую роль. С каждым годом языковые модели становятся все более масштабными и сложными, что приводит к значительному увеличению вычислительных затрат и потреблению памяти. Одна из главных задач исследователей и инженеров — создание систем, способных одновременно поддерживать высокое качество работы и минимизировать издержки на вычисления. В этом контексте особенный интерес представляет концепция Mixture-of-Recursions (MoR), недавно представленная в научном сообществе. Она предлагает уникальный подход, объединяющий две ключевые стратегии повышения эффективности — параметрическое повторное использование слоев и адаптивную вычислительную глубину на уровне отдельных токенов.
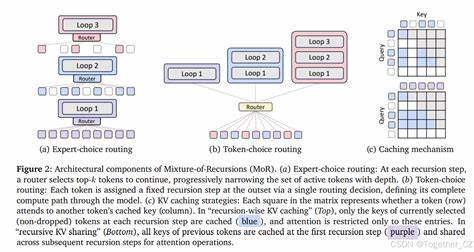
Mixture-of-Recursions основывается на идее Recursive Transformer — архитектуры, в которой один и тот же стек слоев применяется повторно. Это повторное использование слоев позволяет существенно снизить количество параметров модели, ведь вместо создания единственного глубокого стека, система динамически углубляется, используя один и тот же набор слоев раз за разом. Такой подход ведет к значительной экономии оперативной памяти и одновременно сохраняет мощность представлений, необходимых для решения сложных языковых задач. Однако ключевой инновацией MoR является наличие легковесных маршрутизаторов, которые принимают решение о глубине рекурсии для каждого отдельного токена. Вместо того, чтобы каждый входной элемент обрабатывался фиксированным количеством слоев, модель динамически определяет — сколько «обдумываний» и трансформаций потребуется конкретному токену для получения оптимального результата.
Такая адаптивность позволяет значительно сократить вычисления, так как далеко не все токены нуждаются в полном проходе через все рекурсивные слои. Эффект оказывается двойным: ускоряется работа, уменьшается использование памяти, и вместе с тем качество предсказаний не страдает. Еще одним интересным аспектом MoR стала оптимизация внимания с помощью избирательного кэширования ключей и значений (key-value pairs). В классических трансформерах внимание вычисляется на всех токенах, что приводит к квадратичному росту затрат при увеличении длины последовательности. В MoR внимание сосредоточено только на активных на данном уровне рекурсии токенах, что уменьшает объем вычислений и улучшает эффективность памяти.
Дополнительно, в варианте с разделяемыми ключами и значениями, модель переиспользует ранее вычисленные пары для уменьшения задержек при инициализации и снижения потребления памяти, что особенно важно для приложений с требованиями к низкой латентности. Исследования, проведенные авторами, охватывают модели от 135 миллионов до 1,7 миллиардов параметров. Результаты демонстрируют, что MoR задаёт новую границу эффективности — при равных затратах вычислительной мощности и меньшем объёме модели достигается более низкое значение perplexity на валидационных данных и повышенная точность в режиме few-shot обучения. Это означает, что модель становится более умной и экономной одновременно, снижая затраты на обучение и инференс без потери качества. Новые возможности, открываемые Mixture-of-Recursions, имеют огромное значение для развития языковых моделей и ИИ в целом.
С ростом требований к масштабируемости и быстродействию, особенно на уровне коммерческих решений, такой подход может стать ключевым инструментом в балансировке между скоростью, качеством и стоимостью эксплуатации. Кроме того, MoR способствует более устойчивому развитию искусственного интеллекта, снижая энергетические и материальные затраты на обработку данных. Это не только техническое улучшение, но и важный шаг на пути к экологически ответственным технологиям в сфере машинного обучения. Будущее за гибкими и адаптивными архитектурами, и Mixture-of-Recursions предлагает убедительное направление, в котором можно двигаться. Предоставляя эффективный баланс между повторным использованием параметров и токен-специфичной адаптацией глубины обработки, MoR задаёт новый стандарт для создания масштабируемых, экономичных и мощных языковых моделей.
В заключение стоит отметить, что для практического внедрения данной методики доступны исходные коды и подробная документация, что облегчает интеграцию MoR в существующие системы и способствует развитию сообщества исследователей в области обработки естественного языка. Таким образом, Mixture-of-Recursions становится не просто теоретической новинкой, а реальным решением вызовов современного машинного обучения, способным сделать ИИ более доступным и эффективным. Продвинутые модели на основе MoR могут найти применение в самых различных сферах — от улучшения поисковых систем и автоматического перевода до сложных систем поддержки принятия решений и генерации текстов. С каждым днем возрастает значение оптимизации, и инновационные подходы, которые предлагает Mixture-of-Recursions, несомненно, займут в этом процессе центральное место.