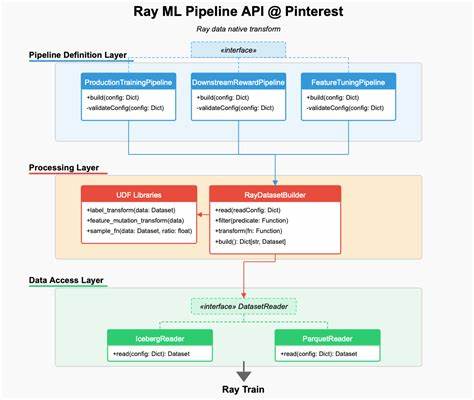
Мир современных технологий стремительно развивается, особенно в области машинного обучения и искусственного интеллекта. Компании, которые работают с большими объемами данных, ежедневно сталкиваются с необходимостью быстрого и эффективного создания моделей, обработки данных и автоматизации процессов. Pinterest, одна из крупнейших визуальных поисковых платформ с более чем 300 миллиардами идей, успешно решает эти задачи благодаря масштабной трансформации своей ML-инфраструктуры. Ключевую роль в этом процессе сыграл Ray — распределённый вычислительный фреймворк, который изначально применялся в Pinterest в контексте обучения и инференса моделей, но затем был расширен для поддержки всего ML-стека от разработки признаков до экспериментов с метками и развертывания конвейеров. Ранее Pinterest сталкивался с множеством вызовов, связанных с традиционными инструментами построения ML-процессов.
Ограниченная скорость и высокая стоимость обработки данных, длительные задачи обратного заполнения (backfill) признаков, а также неэффективные методы выборки и экспериментов с метками тормозили развитие и внедрение новых алгоритмов. Использование Spark для выполнения тяжелых джойн-запросов между наборами данных создавал значительные задержки и сложности в оптимизации ресурсов, что негативно сказывалось на общей скорости итераций. В условиях постоянного роста объёмов данных и усложнения моделей возникла необходимость переосмысления всего подхода к ML-инфраструктуре. Pinterest решила нарастить потенциал Ray и интегрировать его глубже в все этапы жизненного цикла модели. Благодаря созданию нового ядра с Ray Data, компании удалось разработать нативный API для трансформации данных, который заменил медленные и громоздкие Spark-процессы.
Новый API позволил инженерам обрабатывать данные и создавать признаки прямо в обучающих конвейерах, значительно сократив время предварительной обработки и облегчая перенос кода между системами. Одним из прорывных решений стала технология Iceberg Bucket Joins, внедренная в Ray Data. Эта реализация сделала возможным динамичное объединение данных из разных источников непосредственно во время выполнения задач, избавив команду от необходимости создавать огромные предварительные таблицы. Такой подход позволил снизить аппаратные затраты и поднять скорость итераций в 10 раз, что существенно изменило рабочие процессы инженеров. Специальные алгоритмы сопоставления партиций и гибкие стратегии соединения обеспечивают сбалансированность между использованием памяти и быстродействием, а поддержка разных вариантов джойна повышает адаптивность системы под разные данные.
Большое внимание в Pinterest уделили проблеме хранения и повторного использования уже вычисленных признаков. Ранее из-за отсутствия механизма кэширования приходилось повторять тяжелые вычисления при каждом эксперименте, что замедляло процесс и увеличивало расходы. Внедрение возможности записи трансформированных данных в хранилище Iceberg с помощью Ray Data сильно упростило и ускорило как стадию гиперпараметрического тюнинга, так и дальнейшее развертывание моделей. Благодаря тому, что сохраняемые признаки можно оперативно интегрировать в производственные конвейеры и системы хранения, компания снизила время вывода новых фич в продакшн и повысила качество моделей. Для обеспечения максимальной производительности при работе с большими объемами данных в Pinterest оптимизировали базовые структуры Ray Data.
Работа над устранением излишних операций, таких как избыточное объединение блоков и копирование данных, позволила улучшить пропускную способность и снизить нагрузку на вычислительные ресурсы. Особое внимание уделялось оптимизации пользовательских функций (UDFs), которые помогают фильтровать и агрегировать данные. Использование техники JIT-компиляции с помощью Numba и объединение UDF в единые трансформации уменьшили накладные расходы и устранили узкие места в обработке. Обновленная ML-инфраструктура Pinterest, целиком построенная на Ray, стала ярким примером комплексного технологического подхода, где единая платформа берет на себя обработку данных, обучение моделей, экспериментирование и развертывание. Благодаря такому решению сокращение времени итераций достигло десятикратного уровня, а инфраструктурные затраты существенно оптимизировались.