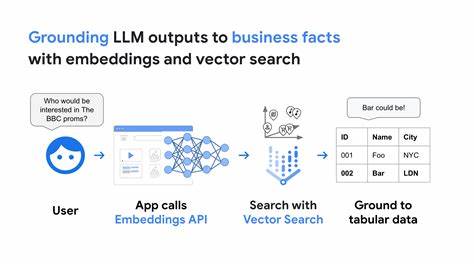
Современные технологии искусственного интеллекта стремительно развиваются, внедряя всё более сложные решения для обработки естественного языка. Одним из ключевых достижений последних лет стали большие языковые модели (LLM, Large Language Models), которые способны генерировать тексты, отвечать на вопросы и даже вести осмысленные диалоги с пользователями. Однако несмотря на впечатляющие возможности, LLM сталкиваются с определёнными ограничениями, среди которых особенно выделяются ошибки, известные как «галлюцинации» — ситуации, когда модель выдает недостоверную или вымышленную информацию. Для преодоления этих вызовов возникает необходимость прикрепления языковых моделей к проверенным и актуальным источникам данных, таким как базы знаний, в частности Wikidata, которая является крупнейшим проектом структурированных данных и содержит тысячи фактов, связанных друг с другом в виде графа знаний. Проект WQ42 представляет собой инновационный подход, который соединяет потенциал LLM с базой данных Wikidata посредством так называемого tool calling — технологии вызова инструментов.
По своей сути это означает, что модель не пытается самостоятельно хранить все знания и выполнять сложные вычисления, а делегирует часть задач специализированным сервисам. При этом сам процесс взаимодействия моделей с Wikidata построен на последовательной интеграции нескольких инструментов, что обеспечивает достоверность, актуальность и обоснованность выдаваемых ответов. Критически важным элементом системы является возможность для модели идентифицировать сущности из пользовательского запроса и сопоставлять их с их Wikidata-идентификаторами (QID). Для этого в WQ42 используется специальный инструмент get_wikidata_qid_for_title, который при передаче любого поискового названия по API возвращает набор возможных совпадений. Модель анализирует эти результаты, распознаёт контекст и выбирает наиболее релевантный QID.
Например, запрос «Нил» может давать несколько результатов — название музыкальной группы, мужское имя и название реки — однако с помощью контекстного анализа LLM выбирает корректный объект. После определения подходящего QID запускается следующий вызов — get_wikidata_information_for_qid, который извлекает из Wikidata текстовую информацию в формате Markdown. Это важный этап, поскольку он превращает сложную и разрозненную структуру графа знаний в связный и понятный для модели текстовый формат. Разработчик проекта реализовал продуманную логическую группировку информации, объединяя схожие атрибуты, например, все виды имен, семейные связи, карьерные данные и награды для биографий людей. Такое упорядочивание помогает избежать эффекта «контекстного рота» — ухудшения качества генерации из-за разбросанных и несфокусированных данных.
Одним из вызовов современных LLM является слабая способность к точным аналитическим вычислениям, особенно если требуется сравнивать или математически обрабатывать данные. WQ42 предлагает элегантное решение — использовать tool calling для запуска специализированного окружения, где модель генерирует краткие скрипты на языке Lua, исполняющиеся в безопасной песочнице. Это позволяет выполнить точные вычисления, например, подсчитать количество букв в слове, сравнить длины рек или вычислить возраст человека на основе даты рождения. Такой метод значительно повышает точность и надёжность ответов. Особенностью WQ42 является отказ от использования векторных баз данных и методов Retrieval Augmented Generation (RAG), которые стали популярной практикой для интеграции KGs (Knowledge Graphs) с LLM.
Вместо сложной векторизации и поиска по эмбеддингам, здесь реализуется прямая работа с текущими свежими данными Wikidata через API и текстовую конвертацию, что исключает зависимость от устаревших обученных моделей и обеспечивают актуальность информации. Для успешной интеграции всех компонентов применяется чётко сформулированный промпт, который задаёт модельной установке правила работы и стиль вывода. Модель обучается строго опираться на данные из инструментов, не делать предположений, включать ссылки с QID в ответ, а также аккуратно представлять мультимедийные форматы — изображения, аудио и видео — удобным для пользователя способом. Если ответа в базе нет, система честно сообщает о невозможности предоставить данные и даже призывает к редактированию Wikidata, тем самым подчеркивая ценность сообществной работы над базой знаний. Примеры использования WQ42 подтверждают его функциональность и практичность.
Ответы на простые вопросы о произведениях писателей, музыкальных группах, биографиях знаменитостей даются быстро и компактно с указанием источников. В более сложных сценариях — многократных запросах к разным сущностям — система удерживает контекст и корректно извлекает данные. Примером успешной обработки может служить вопрос сравнения даты предоставления независимости нескольких стран, где даже небольшие ошибки в названии не мешают системе корректно реконструировать информацию благодаря способности к языковому распознаванию. Тем не менее, проект сталкивается с ограничениями, присущими многим современным системам, интегрирующим LLM и KGs. Некоторым задачам, например тем, что выходят за рамки записанных фактов — как объяснения природных процессов или описания практических навыков — ответить невозможно из-за отсутствия связанных данных.
Также полностью сложные аналитические многозадачные запросы пока решаются частично, поскольку требуется дополнительный инструментарий для сложного логического вывода и агрегации данных. Важным направлением дальнейшего развития может стать интеграция с Wikifunctions — развивающейся энциклопедией функций, что даст модели возможность обращаться не только к статичным фактам, но и к вычислительным процедурам. Это обеспечивает более сложные и динамически вычисляемые ответы. Также актуальна задача расширения языкового охвата, ведь на данный момент LLM лучше всего справляются с английским и несколькими европейскими языками, а адаптация к многим другим языкам открывала бы доступ к знаниям более широкой аудитории. Текущие возможности API Wikidata, такие как wbsearchentities, ограничены поиском по заголовкам.
Усовершенствования в сторону поиска по всему содержимому элемента и его свойствам могли бы значительно расширить круг вопросов, на которые можно получить ответы. Это особенно важно для нерелевантных и запутанных запросов, требующих глубокого поиска. Сравнение с другими методами, например, генерацией SPARQL-запросов, также является интересной темой для исследования. SPARQL позволяет эффективно формулировать сложные запросы к базе знаний, но требует специальной подготовки и знаний. WQ42 же ориентируется на максимальную простоту взаимодействия для конечного пользователя, скрывая сложность за вызовами инструментов и генерацией текстов.
Проект WQ42 — это пример того, как можно обеспечивать точные, своевременные и основанные на реальных фактах ответы, используя мощь современных языковых моделей в связке с богатствами открытых баз знаний. Его архитектура продемонстрировала, что отказ от обширных векторных репрезентаций и ставка на explicit tool calling и текстуализацию может быть эффективной и сохранит актуальность знаний даже при динамическом обновлении информации. Наконец, WQ42 — это пространство для дальнейших исследований и экспериментов, возможность понять ограничения и потенциал технологии agentic AI в контексте доступных знаний. Использование структуры и гибкости Wikidata, а также инструментальных возможностей, таких как выполнение кода на Lua, открывает новые перспективы для создания приложений, которые не только понимают запросы, но и дают точные и актуальные ответы без ненужных допущений. Для тех, кто заинтересован в углубленном понимании темы и желает поэкспериментировать, доступен публичный инструмент по адресу https://wq42.
toolforge.org, а исходный код проекта открыт и написан на языке Rust, что способствует возможностям дальнейшей кастомизации и интеграции. Таким образом, WQ42 предлагает новый взгляд на решение одной из центральных проблем искусственного интеллекта — как обеспечить достоверность и точность ответов LLM, опираясь на разрастающуюся и постоянно обновляющуюся базу знаний Wikidata, используя разумное взаимодействие с внешними инструментами и вычислительными средами. Этот подход открывает пути для создания более надежных интеллектуальных систем, способных превращать большие объемы структурированных данных в полезную информацию для пользователей по всему миру.