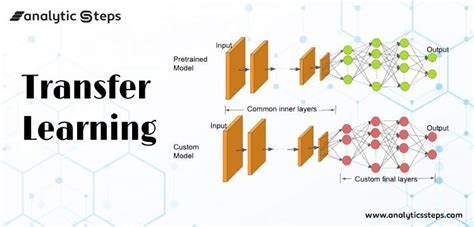
Компьютерное зрение прочно вошло в современные технологии, охватывая разнообразные сферы от медицины до автономного вождения. Одним из ключевых методов, который значительно ускорил и упростил разработку интеллектуальных систем, стало трансферное обучение. Это инновационный подход, позволяющий использовать знания, полученные на больших и разнообразных датасетах, для решения новых задач с ограниченными ресурсами. В условиях, когда сбор и разметка данных — длительный и затратный процесс, трансферное обучение выступает важным инструментом повышения эффективности и качества моделей. Суть трансферного обучения заключается в переносе знаний, приобретенных одной нейронной сетью при обучении на определенном массиве данных, на другую задачу, отличающуюся по контексту или специфике.
Это даёт возможность избежать обучения моделей с нуля, что требует огромных вычислительных мощностей и времени. В результате можно получить высокоточные и надёжные решения, адаптированные к новым предметным областям. Основной механизм трансферного обучения включает в себя два этапа: извлечение признаков и дообучение (fine-tuning). Предобученные модели, такие как ResNet, VGG или Inception, обучаются на огромных базах изображений, таких как ImageNet, где они учатся выделять базовые и сложные визуальные паттерны. При переносе знаний с замороженными низкоуровневыми слоями и адаптацией верхних слоев под целевую задачу модель становится чувствительной к новым особенностям, сохраняя обобщенную способность распознавания.
Такой подход значительно сокращает необходимость в больших размеченных наборах данных для конкретных задач, что особенно ценится в узкоспециализированных или медицинских приложениях. Кроме классических предобученных моделей существует возможность создания собственных специализированных моделей путём дополнительной настройки базовых архитектур на внутренние дата-сеты, что повышает релевантность и точность предсказаний. Важным направлением современного исследования в трансферном обучении являются трансферные энкодеры, примером которых служат модели BERT и T5 в области обработки естественного языка. Они демонстрируют гибкость и эффективность переноса знаний не только в текстовых данных, но и в мультимодальных системах, приближая компьютерное зрение к более комплексным задачам. Практическое применение трансферного обучения охватывает множество областей.
В задачах классификации изображений использование трансферных моделей позволяет достигать высоких результатов при минимальных усилиях. Обнаружение объектов также выигрывает от предобученных сетевых архитектур, таких как Faster R-CNN или YOLO, которые после донастройки показывают высокую скорость и точность даже на небольших выборках. Для сегментации изображений технологии на основе U-Net и Mask R-CNN позволяют выделять объекты с детальным разграничением, что критично для медицинской диагностики, где точность границ опухолей или патологий имеет первостепенное значение. Автономный транспорт и системы помощи водителю используют трансферное обучение для распознавания дорожных знаков, пешеходов и других участников дорожного движения в условиях реального времени и различных погодных условий. Это позволяет значительно повысить безопасность и надежность работы подобных систем.
Несмотря на явные преимущества, трансферное обучение сталкивается с рядом вызовов. Крупные модели требуют значительных вычислительных ресурсов, особенно при дообучении. Иногда присутствует несоответствие между исходным датасетом и новой предметной областью, что приводит к снижению эффективности. Именно здесь необходимы дополнительные методы адаптации и увеличения данных с помощью аугментаций для повышения обобщающей способности моделей. Кроме того, понимание того, как происходит перенос знаний и какие признаки используются моделью, становится критически важным в сферах с высокими требованиями к интерпретируемости и прозрачности, например, в медицине.
Для успешного использования трансферного обучения рекомендуется начинать с признанных предобученных моделей, которые доказали свою эффективность. Эффективное управление размером модели через методы обрезки (прунинга) помогает сделать модели более компактными и быстрыми. Выбор архитектур с оптимизированными слоями для извлечения признаков и адаптации позволяет добиться баланса между точностью и производительностью. Использование разнообразных техник аугментации повышает устойчивость модели к новым и нетипичным данным. Более сложные стратегии, такие как покадровая релевантность, способствуют лучшей интерпретации результатов и повышают общую эффективность обучения.
Для практического освоения технологии представлены примеры кода на популярных фреймворках. В TensorFlow можно взять за основу модель ResNet50V2 с весами ImageNet, заморозить начальные слои, добавив собственные полносвязные слои для классификации целей нового датасета. При этом используют расширение данных с помощью ImageDataGenerator, что улучшает обобщение модели. В PyTorch пример с Faster R-CNN демонстрирует, как изменить последний слой классификации под нужное число классов, установить якоря и настроить RPN для улучшения скорости и качества распознавания объектов. Подключение предобученных весов и применение нормализации входных данных повышает качество обучения.