Отладка программного обеспечения – один из самых трудоемких и важных этапов разработки, от успешного прохождения которого зависит качество и стабильность конечного продукта. С годами появились сотни методик, инструментов и подходов для выявления и исправления ошибок. Среди них выделяется относительно простая, но при этом очень мощная техника, известная как дифференциальное покрытие кода. Она позволяет наглядно увидеть различия в охвате кода между успешными и неуспешными тестами, помогая быстро локализовать проблемные участки и тем самым сокращать время поиска ошибок. В основе метода лежит анализ покрытия кода — информации о том, какие строки или блоки исполняемого кода были выполнены во время запуска теста.
В традиционном тестировании статистика покрытия помогает оценить полноту тестовых сценариев. Однако, когда дело доходит до выявления причины сбоя, просто знать, что покрытие составляет, например, 85%, недостаточно. Здесь на помощь приходит дифференциальное покрытие, которое фокусируется не на общей статистике, а на разнице между профилями покрытия успешных и неуспешных тестов. Этот метод особенно полезен в условиях, когда в проекте уже существует набор тестов, и обнаружился один неудачный сценарий. Вместо бессмысленных попыток гадать, где спряталась ошибка, разработчик может сравнить профили покрытия кода, собранные для успешных запусков тестов, и для конкретного ошибочного случая.
Код, который был выполнен только во время провалившегося теста, с высокой вероятностью содержит участок с багом или связан с ним по цепочке логики. Дифференциальное покрытие дает две основные группы информации. Во-первых, зеленые участки, которые выполняются только в неудачном тесте. Они привлекают наибольшее внимание, поскольку могут содержать источник ошибки. Во-вторых, красные участки, покрытые в успешных тестах, но пропущенные в провалившемся.
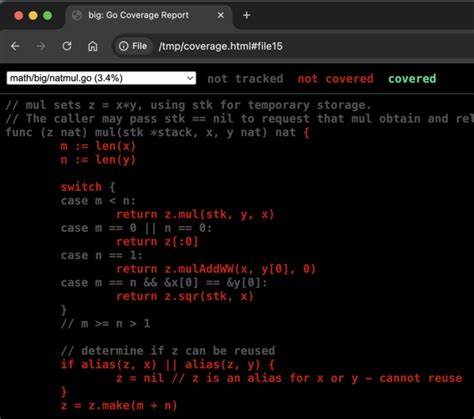
Они помогают исключить части кода, которые точно не вызывают сбой, а также понять, какие логические ветвления или функции не были задействованы в проблемном сценарии. Такой анализ помогает понять контекст и логику, стоящую за отказом. Практическое использование дифференциального покрытия очень простое и не требует дорогостоящих сложных систем. Например, в среде разработки Go достаточно собрать профили покрытия для наборов тестов, исключающих и включающих определенный тест, после чего с помощью стандартных утилит провести diff профилей и получить чистый профиль, отображающий уникально выполненный код. Визуализация с помощью html-отчетов позволяет быстро и наглядно определить подозрительные участки.
Применение этого подхода доказало свою эффективность в реальных кейсах. В одной из известных историй использования метода, была вставлена ошибка в знаменитую библиотеку math/big. Профиль покрытия показал, что только один небольшой файл имеет непокрытые или уникально покрытые строчки, что резко сузило поле поиска с тысяч строк кода до нескольких целевых строк. В итоге причину ошибки удалось быстро обнаружить — неправильное выставление логического флага, приводившее к некорректному выводу. Без дифференциального покрытия отладка, возможно, заняла бы гораздо больше времени и потребовала бы глубокого понимания всего кода.
Важно понимать, что дифференциальное покрытие не решает все проблемы отладки и не является универсальной панацеей. Если баг зависит от редких данных или состояние программы сложно воспроизвести, код может выполниться как во время успешных, так и провальных тестов. В таких случаях стоит применять более комплексные средства и методы отслеживания. Тем не менее, данный подход существенно повышает информативность анализа и ускоряет процесс нахождения ошибок, особенно когда сбой явно связан с уникальным поведением конкретного теста. Кроме поиска ошибок, дифференциальное покрытие можно успешно применять для понимания и документирования кода.
Например, чтобы узнать, какие сегменты реализации активируются при запуске определенного функционала или модуля, достаточно собрать профиль покрытия с и без запуска целевого сценария, а затем сравнить их. Это особенно полезно для больших проектов с множеством функций и сложными ветвлениями, где ручное отслеживание логики потребовало бы значительных затрат времени и усилий. Внедрение дифференциального покрытия в процесс разработки не требует значительных затрат и сочетается с уже существующими практиками тестирования и CI/CD. Инструменты покрытия доступны во многих языках программирования и их экосистемах, что делает метод универсальным и практичным. Его можно эффективно интегрировать в пайплайны непрерывной интеграции, чтобы автоматически выявлять проблемные участки при появлении новых ошибок, тем самым значительно сокращая время реакции команд разработки.
Также важно отметить, что кроме традиционного детального текста покрытия, существуют удобные графические интерфейсы и визуализаторы, которые помогают даже менее опытным специалистам разобраться, куда смотрит программа при выполнении теста и какие участки ведут себя иначе в случае сбоя. Такой визуальный анализ облегчает коммуникацию внутри команд и повышает общую культуру качества программного обеспечения. В процессе развития инструментов диагностики программных ошибок дифференциальное покрытие кода стало надежным помощником, позволяющим сделать процесс отладки более структурированным, прозрачным и результативным. Оно служит мостом между сырыми данными о тестах и реальным пониманием причин сбоев, а также способствует более глубокому анализу уже работающего кода. Заключая, дифференциальное покрытие — это мощный диагностический инструмент, который помогает определить проблемные участки кода через сопоставление профилей покрытия успешных и неудачных тестов.
Это облегчает локализацию ошибок, экономит время и усилия программистов и повышает качество конечного продукта за счет точечного анализа. При принятии во внимание возможных ограничений и разумном использовании, этот метод обязательно станет достойной частью арсенала любого разработчика и команды, стремящейся к высоким стандартам в отладке и тестировании программного обеспечения.