В современном мире обработка данных занимает центральное место в работе аналитиков, инженеров и разработчиков. Несмотря на широкое распространение электронных таблиц и баз данных, формат PDF остаётся одним из самых популярных способов представления информации, особенно в финансовой, юридической и административной сферах. Однако извлечение данных из PDF-документов сопряжено с серьёзными сложностями, особенно когда речь идёт о систематическом парсинге при помощи Python. Разберёмся, с какими вызовами предстоит столкнуться и каким образом их можно преодолеть. Одной из главных проблем является высокая затратность времени на создание и поддержание надёжной системы парсинга.
Первичная реализация, включающая написание скриптов на Python, кажется простой задачей, поскольку базовые библиотеки позволяют извлекать текст и структурированные данные. Однако на практике, когда речь идёт о десятках и сотнях файлов с различными форматами, качественное извлечение информации становится крайне трудоёмким. Необходимость валидации и нормализации данных, оптимизации производительности, а также обработке исключительных случаев требует значительных усилий и ресурсов со стороны разработчиков и инженеров. Ключевая сложность также заключается в природе самих PDF-документов. В отличие от таблиц или баз данных, PDF создавался как формат для визуального отображения, а не хранения структурированных данных.
Вследствие этого содержание часто представлено в смешанном виде: текст, графики, таблицы, изображения и даже вложенные элементы часто расположены без чёткой логики и последовательности. Особенно это осложняет работу с многостраничными документами, где важная для анализа информация может располагаться на разных страницах в произвольном порядке. Важным аспектом становится проблема сложности макета документа. Форматы с много- или двуколоночной версткой доставляют особые трудности, так как стандартные средства построчного чтения обычно не распознают разделение на колонки и выдают смешанный текст. Дополнительные слои сложности создают вложенные таблицы, когда одна таблица содержит другие таблицы внутри себя.
Проверенные библиотеки могут некорректно воспринимать такую структуру, что приводит к искажённым или неполным результатам. Часто присутствуют динамические элементы, такие как повторяющиеся заголовки и колонтитулы, которые нужно уметь отличать от основного содержимого, иначе итоговые данные окажутся шумными. Особое внимание необходимо уделить работе с PDF-файлами, основой которых являются изображения. Такие документы, получаемые путём сканирования бумажных оригиналов, не содержат в себе текст и требуют применения технологий оптического распознавания символов (OCR). Популярные инструменты, например, Tesseract, зачастую оказываются недостаточно точными при низком качестве сканов, нестандартных шрифтах или сложных фонах.
Это означает, что даже при использовании OCR данные требуют дополнительной проверки и коррекции, чтобы избежать ошибок и неточностей в распознавании. Правильное и точное извлечение данных из объемных и комплексных PDF-документов представляет собой отдельную задачу. Часто в таких файлах встречаются одинаковые показатели, представленные в различных вариациях и форматах. Например, финансовые отчеты или отчёты SEC содержат таблицы с различными типами доходов и затрат, отражающие разные методики расчёта и функциональные подразделения внутри компании. Умение идентифицировать эти различия и предавать им правильное значение критично для корректного анализа и последующей обработки.
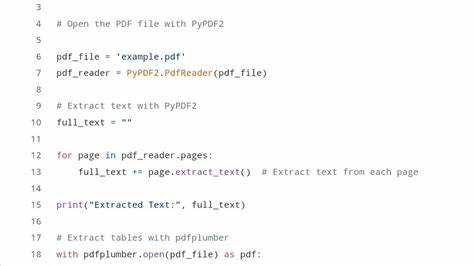
Обработка больших и тяжёлых файлов создаёт дополнительные узкие места производительности. Стандартные библиотеки Python, которые загружают файлы целиком в оперативную память, могут столкнуться с проблемами, если объём данных значителен. Задержки и даже сбои становятся частыми при попытке обработать многостраничные отчёты или высококачественные сканы, что требует реализации дополнительных механизмов параллельной обработки или управления ресурсами. Для решения перечисленных проблем разработаны специализированные библиотеки и инструменты, учитывающие особенности парсинга PDF. Например, PyPDF2 ориентирована на работу с электронными текстовыми PDF, позволяя извлекать, изменять или разбивать документы.
Библиотека pdfplumber обладает расширенным функционалом для извлечения структурированных данных, таких как таблицы и позиционная информация, что особенно полезно при работе с отчётами и сложными макетами. Для сканов и изображений наиболее подходящим решением является использование OCR-инструментов, например, Pytesseract, зачастую в комбинации с библиотекой pdf2image для конвертации страниц в изображения. Современные технологии крупных языковых моделей (LLM), такие как ChatGPT с возможностью обработки изображений, предоставляют новые пути упрощения парсинга PDF. Эти модели способны понять и интерпретировать содержимое и структуру документа, что позволяет обойти необходимость подробного программирования правил и вручную прописанных скриптов. Вместо этого пользователи могут задавать естественно-языковые запросы, а модель самостоятельно извлечёт нужные данные, что значительно ускоряет рабочий процесс.
Для тех команд, которые ограничены во времени или технических ресурсах, существуют облачные решения, например, Roe.ai. Этот сервис позволяет загружать PDF-документы и задавать SQL-подобные запросы для получения информации без написания кода. Полезность таких платформ заключается в снижении порога входа и ускорении вывода результатов, что особенно актуально для анализа резюме, финансовых файлов и других больших массивов данных. Эффективный подход к парсингу PDF с помощью Python часто требует сочетания нескольких инструментов, каждое из которых решает свою задачу.
Например, использование PyPDF2 для извлечения чистого текста, pdfplumber для анализа таблиц и Pytesseract для распознавания текста из изображений позволяет охватить широкий спектр форматов и качественно собрать данные. Непрерывное тестирование и проверка качества извлечённой информации обязательны для создания надёжной системы, поскольку ошибки и пропуски в исходных данных могут привести к неправильным выводам и потерям в бизнес-процессах. Стоит отметить, что несмотря на сложность задачи, взаимодействие с PDF остаётся актуальной и востребованной областью, позволяющей автоматизировать традиционно ручные операции и повысить продуктивность. Постоянное развитие технологий в области компьютерного зрения, понимания естественного языка и облачных сервисов открывает новые возможности для совершенствования методов парсинга. При грамотной организации процесса, использованием современных инструментов и тщательно продуманной архитектуры можно значительно снизить временные и ресурсные затраты.
Таким образом, основные сложности при парсинге PDF-файлов с помощью Python связаны с разнообразием форматов и макетов документов, необходимостью обработки как текстовых, так и сканированных материалов, а также требованиями к производительности в работе с большими объёмами данных. Для успешного извлечения информации важно применять комплексный подход, объединяя различные библиотеки и технологии, а также учитывать возможности современных моделей искусственного интеллекта. Это позволит построить надёжные и масштабируемые решения, которые обеспечат высокий уровень качества данных и сделают работу с PDF более управляемой и эффективной. .







