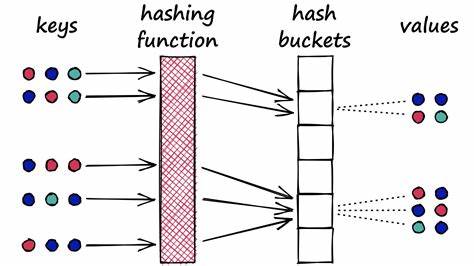
В современном мире, где объемы данных растут с небывалой скоростью, эффективный и быстрый поиск по большим информационным массивам становится одной из ключевых задач. Обычные методы сравнения объектов в таких хранилищах данных зачастую оказываются слишком медленными или ресурсоемкими, вызывая необходимость использования более изощренных алгоритмических подходов. Одним из таких решений является метод локально-чувствительного хеширования, известный по английскому названию Locality-Sensitive Hashing (LSH). Данная технология позволяет значительно ускорить поиск объектов, сходных по смыслу или структуре, в объемных и высокоразмерных пространствах данных. Локально-чувствительное хеширование представляет собой класс алгоритмов, которые преобразуют объекты таким образом, что близкие по определенной метрике элементы с большой вероятностью попадают в одинаковые хеш-корзины, а далекие — в разные.
Это резко отличает LSH от классической хеш-функции, главной целью которой является сокрытие коллизий. Смысл применения LSH – не минимизировать совпадения между разными объектами, а максимизировать вероятность того, что похожие объекты будут иметь одинаковые хеш-значения. За счет такой особенности достигается высокая скорость поиска ближайших соседей и обнаружения сходств среди больших объемов данных. Основные алгоритмы, относящиеся к локально-чувствительному хешированию, делятся на разные типы в зависимости от того, какую метрику сходства они используют. Например, битовая выборка в Хэмминговом пространстве служит для бинарных данных, где важно выявить векторы с минимальным числом отличающихся бит.
MinHash основан на операциях с множествами и применяется в задачах анализа сходства по индексу Жаккара, что особенно актуально при обработке наборов ключевых слов, документов и интернет-страниц. Кроме того, существует метод случайных проекций, который основывается на угловом сходстве и косинусном расстоянии. Он широко применяется в анализе текстовых данных и векторных представлений слов в области обработки естественного языка. Особенностью LSH является возможность «усиления» гарантии точного попадания похожих объектов в одну корзину с помощью техник, известных как AND- и OR-конструкции. Простейшая идея состоит в том, чтобы объединить несколько базовых хеш-функций для уменьшения вероятности ложных совпадений прежде всего между далекими объектами и одновременно повысить вероятность совпадения для близких, тем самым повысив точность и надежность алгоритма.
Современные применения локально-чувствительного хеширования крайне разнообразны и простираются от задач поиска дубликатов и кластеризации данных до биоинформатики и компьютерной безопасности. Например, в индустрии информационного поиска LSH используется для быстрого нахождения похожих документов, изображений или аудиофрагментов, что важно для борьбы с информационным шумом и спамом. В биоинформатике этот метод облегчает сопоставление геномных последовательностей и анализ биологических данных, ускоряя процесс выявления схожих участков ДНК. Также LSH находит применение в обучении нейронных сетей, где помогает оптимизировать вычислительные процессы при работе с большими наборами данных, а в области безопасности — для создания цифровых отпечатков и обнаружения изменений в программном обеспечении. Важно отметить, что благодаря своей математической основе и вероятностным гарантиям, метод локально-чувствительного хеширования позволяет преодолеть так называемое проклятие размерности, из-за чего стандартные алгоритмы теряют эффективность при работе с высокоразмерными данными.
Это делает LSH особенно ценным инструментом в эпоху биг дата и искусственного интеллекта. Программные реализации LSH доступны в виде открытого кода и используются как в исследовательских проектах, так и в промышленности. Среди известных вариантов можно выделить Nilsimsa и TLSH, применяемые для обнаружения похожих сообщений и обеспечения кибербезопасности. Обучаемые модификации LSH, такие как Learnable LSH, открывают перспективы интеграции алгоритмов с искусственным интеллектом, улучшая адаптивность и точность поиска. Несмотря на все преимущества, локально-чувствительное хеширование имеет и свои ограничения.
Вероятностный характер метода означает, что точность результатов зависит от выбора параметров алгоритма, таких как количество хеш-функций и число хеш-таблиц. Некорректный выбор этих параметров может привести либо к увеличению числа ложных срабатываний, либо к пропуску реально похожих объектов. Тем не менее, благодаря своей масштабируемости и гибкости, LSH остается одним из самых популярных инструментов в современных задачах обработки данных. Глобальные тренды развития технологий и непрерывный рост объемов информации делают методы эффективного поиска ключевыми в обеспечении быстрого и точного доступа к необходимым данным. Локально-чувствительное хеширование способно не только ускорить процессы анализа, но и снизить аппаратные и временные затраты, что крайне важно для компаний различных отраслей.
В заключение, локально-чувствительное хеширование как идея и практический метод доказало свою силу и универсальность. Оно объединяет в себе глубокие математические основы и практическую применимость в различных сферах, от анализа текстов до биоинформатики и безопасности. Овладение этим инструментом даст разработчикам и исследователям мощный рычаг для решения сложных задач в работе с большими данными, позволяя предложить качественно новые подходы к поиску и анализу информации.