Современный мир стремительно развивается в области искусственного интеллекта, и все чаще мы сталкиваемся с задачами, требующими высокой производительности вычислительных устройств. Одним из ключевых факторов успешного выполнения AI-задач является мощность графических процессоров (GPU) и центральных процессоров (CPU). Если ваш компьютер не способен обрабатывать достаточное количество токенов в секунду, эффективность работы с искусственным интеллектом заметно снижается, что влияет на качество и скорость решения задач. В последние годы технология WebGPU стала прорывом в области браузерных вычислений, позволяя запускать сложные модели непосредственно из браузера, без необходимости устанавливать специальные программы. Это открывает новые горизонты для оценки производительности оборудования простыми и доступными способами.
Инструменты вроде AIStats.FYI предлагают легкий браузерный бенчмарк, позволяющий проверить токены в секунду на вашем устройстве с помощью небольших моделей. Основой для таких испытаний служит модель onnx-community/Qwen3-0.6B-ONNX, используемая через библиотеку Transformers.js.
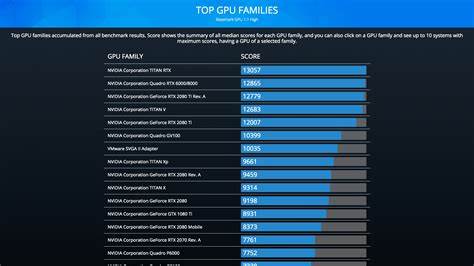
Несмотря на определенные ограничения браузерной среды, такие тесты дают наглядное представление о реальных возможностях вашего железа в обработке AI-задач. Анализ результатов показывает, что современные мощные GPU, такие как NVIDIA GeForce RTX 4090, RTX 3090 Ti или Apple M3 Max и Ultra, способны обрабатывать свыше 70 токенов в секунду, что значительно превышает минимально рекомендуемый уровень в 20 TPS для комфортной работы с искусственным интеллектом. В то же время устройства среднего сегмента с менее мощными GPU демонстрируют показатели в диапазоне 30-50 TPS, что может быть достаточно для базовых и менее ресурсоемких задач, но ограничит возможности для сложных моделей и быстрой генерации текстов. Особое внимание заслуживает растущая производительность мобильных и интегрированных графических решений, таких как Apple M-серии и AMD Radeon RX, которые демонстрируют достойные результаты, позволяя сами по себе запускать AI-модели без подключения к мощным внешним устройствам. Также важно отметить, что браузерные тесты, учитывая накладные расходы самой среды, обычно показывают несколько заниженные результаты по сравнению с нативными бенчмарками, однако предоставляют более доступный и удобный способ предварительной оценки.
Помимо GPU, CPU остается важным компонентом в общей производительности при таких задачах. Многие современные процессоры, обладающие популярными архитектурами и большим количеством ядер, способны поддерживать дополнение GPU в ускорении обработки токенов. При браузерном тестировании наблюдаются результаты, в разы ниже, чем при использовании GPU, что подчеркивает необходимость мощной видеокарты для эффективной работы с современными AI-моделями. Важным аспектом для пользователей является возможность анонимной отправки результатов своих тестов, что позволяет собрать широкую и разнообразную статистическую базу, помогающую отслеживать тенденции в производительности оборудования и выявлять оптимальные решения для различных сценариев. Это также способствует формированию рейтингов и рекомендаций при выборе компьютеров или отдельных компонентов для AI-решений.
Для тех, кто желает проводить более углубленные исследования, на AIStats.FYI предусмотрена возможность загрузить и запустить полноценные нативные бенчмарки, требующие установки вспомогательного ПО Ollama. Через терминал можно запускать тесты для различных систем – Linux с архитектурами x86_64 и ARM64, а также другие платформы, что облегчает получение более точных показателей с учетом аппаратных особенностей. При выборе GPU для искусственного интеллекта следует ориентироваться не только на raw производительность, но и на совместимость с Open Neural Network Exchange (ONNX) форматами, поддерживаемыми в современных фреймворках. Это важно для успешного запуска моделей в браузерах и нативных приложениях.
Оптимизация драйверов и поддержка WebGPU играют ключевую роль в обеспечении плавного взаимодействия между железом и программным обеспечением. Ключевой метрикой в AIStats.FYI является Tokens Per Second (TPS) – количество обрабатываемых токенов за секунду. Минимальный порог, установленный сообществом экспертов, составляет 20 TPS. Если показатели вашего устройства ниже этого значения, вероятнее всего, работать с современными моделями будет неудобно, с задержками и возможными сбоями.
Этот критерий позволяет пользователям быстро определить, подходит ли их аппаратная база для AI-решений или необходимо рассмотреть апгрейд или замену оборудования. Рост популярности браузерных решений для AI не случайен – это шаг к демократизации технологий, предоставляющий возможность быстро и без сложных настроек оценить свои возможности и даже создать прототипы приложений на основе ИИ без громоздкой инфраструктуры. Для разработчиков и энтузиастов доступность инструментов трансформировалась в мощный ресурс для экспериментов и исследований на практике. В заключение отметим, что современные браузерные бенчмарки GPU и CPU для искусственного интеллекта – это важный инструмент как для профессионалов, так и для рядовых пользователей. Понимание того, как именно ваше оборудование работает с AI-моделями прямо в браузере, помогает принимать обоснованные решения при выборе техники и эффективно использовать возможности новых технологий.
Продолжайте следить за новинками, экспериментировать с тестами и участвовать в сообществе, чтобы вместе совершенствовать методы оценки и внедрения AI в повседневную жизнь.


![A Class 99 – The UK's Most Powerful Locomotive [video]](/images/4484A084-5E86-43C1-8E5C-7C2FA6A04546)