Curl – это один из самых популярных инструментов для передачи данных с использованием различных протоколов в интернете. Его кодовая база разрабатывается с использованием языка программирования C, известного своей производительностью и гибкостью. Однако с этими же преимуществами связаны определённые риски: в ходе многолетнего развития curl в его коде были обнаружены многочисленные уязвимости, многие из которых связаны с типичными ошибками программирования на C. Анализ причин и характера этих уязвимостей помогает лучше понять, почему выбор языка влияет на безопасность, и какие уроки можно извлечь для разработки надёжного кода.В языке С нет встроенных средств защиты от распространённых ошибок – например, автоматического контроля за выходом за границы массивов, управлением памятью или защищённым доступом к строкам.
Такие «промахи» легко приводят к серьезным уязвимостям, включая ошибки переполнения буфера, повреждения памяти и возможности исполнения произвольного кода. Curl, будучи достаточно сложным проектом, содержит более 167 задокументированных ошибок, ведущих к уязвимостям, многие из которых можно отнести именно к «ошибкам языка C».Исторически в период с 2016 по 2020 год количество ошибок, связанных с С-кодом в curl, значительно сократилось. Это произошло не из-за резкого изменения подходов или волшебной «переписывания» кода с нуля, а в основном благодаря постоянному улучшению процессов разработки, тестирования и внедрению более современных инструментов анализа кода. Разработчики старательно избегали некоторых опасных паттернов программирования и старались использовать вспомогательные функции, оптимизирующие работу с памятью и строками, что позволяло минимизировать простые, но критичные ошибки.
Важно отметить, что ошибки, обусловленные языком C, были выявлены и устранены во время долгого периода, так как среднее время нахождения уязвимости в релизе curl составляет порядка шести-восьми лет. Этот показатель говорит о высокой сложности обнаружения багов, а также о значении активного сообщества аудиторов и экспертов по безопасности, непрерывно изучающих проект. Несмотря на этот длительный срок, тенденция последних лет демонстрирует улучшение, что также связано с переходом на более качественные процессы разработки и повышением знаний команды по безопасному программированию.Одной из ключевых проблем в контексте ошибок на С язык является управление строками и буферами. В curl используется собственная абстракция динамических буферов (dynbuf), которая значительно уменьшает количество ошибок, связанных с доступом за пределы выделенной памяти и переполнением буфера.
Однако далеко не вся часть кода может использовать эту абстракцию из-за особенностей взаимодействия с внешними библиотеками и необходимости поддерживать устаревший код. В результате возникают ситуации, когда ошибки остаются в частях программы с более «рукопашным» управлением памятью, что не исключает рисков безопасности.Дискуссии внутри сообщества curl касательно возможности перехода на другой язык программирования, например C++, показывают, что подобное решение не является однозначным. Несмотря на потенциальные современные механизмы защиты памяти и удобства, многие C-ошибки возможно допустить и на C++. Опыт разработчиков Firefox, использующих этот язык, показал, что C++ также способен создавать похожие проблемы при отсутствии строгой дисциплины и опыта, вплоть до того, что такой язык сравнивают с передачей огнестрельного оружия ребенку – опасным при неосторожном обращении.
Таким образом, вопрос безопасности в коде curl напрямую связан с природой языка С и менталитетом команды, ответственной за его развитие. Улучшение безопасности требует не просто инструментов, но и усердного труда над культурой разработки, постоянного обучения и адаптации к лучшим практикам. В ряде случаев опыт изучения Rust и его системы заимствований повлиял на стиль написания кода на С и С++, помогая разработчикам мыслить в терминах безопасности и ответственности при работе с памятью.Это подчеркивает, что, несмотря на известные недостатки C, дальнейший успех в снижении количества уязвимостей в curl зависит от множества факторов: качества инструментов анализа, культуры программирования, зрелости процессов тестирования и активного сообщества, регулярно исследующего новый и старый код на предмет ошибок. В будущем возможно появление стандартных библиотек или абстракций, позволяющих более безопасно работать с памятью и строками, однако пока этого на уровне официального языка не наблюдается, поэтому необходимость постоянного внимания к деталям и использованию проверенных практик остается актуальной.
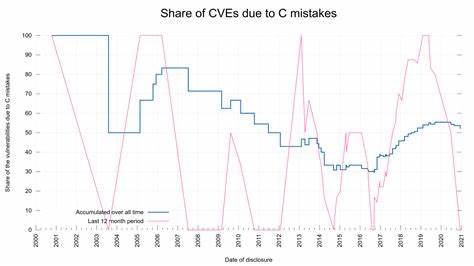
Еще одной важной темой является открытость команды curl к помощи и внешним предложениям. Разработчики неоднократно подчеркивали, что улучшают качество благодаря коллективной работе, и приглашают специалистов содействовать совершенствованию кода и методов проверки. Такой подход задает пример для большинства крупных открытых проектов, где безопасность ощущается как общий вызов и ответственность.С точки зрения поиска и устранения ошибок, графики анализа уязвимостей curl показывают, что обнаружение проблем происходит достаточно быстро. Влияние периода задержек в отчётах заметно, но тенденция такова, что большая часть уязвимостей выявляется и исправляется в относительно короткий срок.
Это поддерживает мнение, что текущие методы анализа и тестирования, включая статический анализ, fuzzing и ревью кода, достаточно эффективны для своевременного выявления многих опасных ошибок.Подводя итог, ошибки на С в curl — это пример того, как выбор языка программирования может существенно влиять на безопасность программного обеспечения. В то же время успехи curl в снижении таких уязвимостей демонстрируют, что с ответственным подходом, инструментами и культурой разработки можно значительно смягчить риски, связанные с использованием далёкого от безопасности низкоуровневого языка. Изучение опыта curl полезно для всех, кто заинтересован в создании надёжных сетевых приложений и управлении рисками в современных программных проектах.