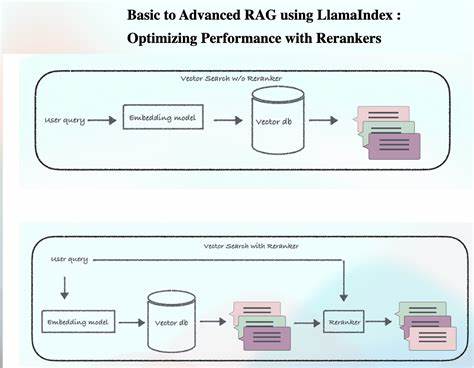
Современный мир цифровых технологий требует максимально точного и быстрого поиска информации в огромных массивах данных. Retrieval-Augmented Generation (RAG) - это прогрессивный подход, который позволяет использовать корпус знаний для формирования развёрнутых и релевантных ответов на запросы пользователей. Ключевым элементом в цепочке RAG выступает этап доранжировки (reranking), при котором результаты первичного поиска упорядочиваются заново с целью повышения их качества и релевантности. В последние годы появились новые возможности благодаря внедрению больших языковых моделей (Large Language Models, LLM) в роли rerankers - механизмов, которые способны не просто оценить тексты по схожести, а понимать их содержимое и контекст на глубоком уровне. Применение LLM rerankers для RAG - реальный прорыв для многих систем, будь то интеллектуальные помощники, системы поддержки клиентов или инструменты автоматизации.
Чтобы овладеть этими технологиями, важно понять их суть, преимущества и сложности. На практике reranking с LLM представляет собой перераспределение результатов поиска, которые были изначально отобраны с помощью векторного поиска. Векторный поиск хорошо находит совпадения по смыслу, но может пропускать нюансы и специфику запроса. Вмешательство LLM позволяет более тонко проанализировать каждый результат, учесть контекст и степень релевантности, что существенно повышает качество конечных ответов. Существует несколько подходов к доранжировке с LLM, главным образом разделяемых на три категории: точечное (pointwise), парное (pairwise) и списковое (listwise).
Точечное ранжирование предполагает, что модель оценивает каждый документ индивидуально и присваивает ему числовую оценку релевантности. Это удобно, прозрачно, и дает понятную метрику для дальнейшей обработки. Парное ранжирование строится на сравнении двух документов и выбору более релевантного из пары. Такой подход может быть качественнее, но требует значительно больше вычислительных ресурсов, так как число сравнений растёт квадратично. Наконец, списковое ранжирование предполагает оценку и упорядочивание всего списка документов за один заход, но нуждается в более мощных моделях и может увеличивать задержки.
В реальном применении часто выбирают точечный способ из-за баланса качества и эффективности. Однако при большом числе исходных результатов (например, 40 и более) возникает другая проблема - длина входных данных и выходных ответов модели может быть слишком большой. Прямое передача всех отобранных документов увеличивает токен-лимит, ухудшая скорость и точность. В решении этих проблем ключевым становится оптимизация формата данных и разделение процесса на параллельные потоки. Сокращение объёма выходных данных, например, за счёт исключения пробелов и оптимизации формата до компактного словаря без излишних символов, позволяет уменьшить количество токенов в ответе модели и ускорить обработку.
Кроме того, введение порога релевантности, ниже которого проходящие документы не включаются в ответ, сокращает объем лишней информации, облегчая интерпретацию и снижая задержки. Параллелизация reranking - ещё одно важное инженерное решение. Деление списка документов на несколько групп и оценка их одновременно разными рабочими процессами уменьшает узкие места в производительности, снижает задержки и позволяет использовать менее дорогие модели без потери качества. Интересный нюанс кроется в методике распределения документов по батчам. Простое разделение подряд идущих документов создаёт дисбаланс, поскольку документы с более высокой исходной релевантностью скапливаются в одном батче, зануляя выгоды параллельной обработки.
Решение состоит в распределении по принципу round-robin, то есть разбрасывании документов с разными позициями по разным пакетам, что нивелирует позиционные искажения. При таком подходе каждая рабочая группа получает представительный набор данных, а итоговый порядок выводится после объединения результатов с использованием дополнительных метрик или моделей для разрешения спорных ситуаций. Помимо технических аспектов, имеет значение устойчивость и надежность системы. При параллельных вызовах моделей вероятность того, что один из потоков откажет или "зависнет", увеличивается. Для смягчения этого эффекта применяются стратегии таймаутов, повторных вызовов и резервных механизмов, например, переключение на более быстрые, пусть и менее точные cross-encoder модели в случае сбоя LLM reranker.
Практическое применение LLM rerankers подтверждает значимые преимущества. В системах поддержки конечных пользователей улучшение качества ранжирования напрямую влияет на коэффициенты успешного разрешения запросов, повышает доверие к сервису и улучшает опыт взаимодействия. Например, в проектах со сложной доменной областью - финансовой аналитике или технической поддержке - рост качества поиска и генерации ответа может сказаться на реальной экономии времени и ресурсов. В частности, оптимизации, внедрённые в различных промышленных решениях, позволяют снизить задержки с нескольких секунд до менее секунды при сохранении точноти результатов и снижении операционных затрат в 8 раз. Чтобы ещё более повысить качество и в то же время снизить вычислительные потребности, современные команды разработчиков всё чаще используют LLM rerankers как учителей для обучения кастомных, более легковесных моделей reranking.
Эти модели, основанные на знаниях, полученных от больших языковых моделей, демонстрируют хорошие показатели качества и значительно ускоряют процесс обработки. Еще один важный аспект - поддержание разнообразия источников при комбинировании результатов из разных типов данных, например внутренних документов, публичных статей и пользовательских историй. Если не разделять поток информации по источникам, более обильные или частые типы данных могут доминировать на верхних позициях, снижая качество конечного ответа. Продвинутая архитектура, предполагающая независимый reranking по типам и последующую интеграцию, помогает сохранять баланс и обеспечивать богатство и достоверность информации. В результате методики с использованием LLM rerankers кардинально меняют подход к созданию интеллектуальных систем.
Они позволяют не просто искать ближайшие совпадения, а глубже понимать смысл запросов, выявлять скрытые потребности пользователей и формировать качественные, четкие и полезные ответы. При этом практичные инженерные решения с оптимизацией токенов, параллельной обработкой и тщательной калибровкой позволяют внедрять такие технологии на реальных продуктивных системах с высокими требованиями к скорости и надежности. Интерес для бизнеса и разработчиков представляет также открытый доступ к продуманным шаблонам и промтам, которые помогают стандартизировать и упростить внедрение LLM rerankers для разных кейсов. Благодаря прозрачности градации оценок релевантности, с чёткими критериями от исключительной релевантности до полной нерелевантности, значительно упрощается интерпретация результатов модели и последующая автоматизация обработки. Можно отметить, что использование больших языковых моделей в роли rerankers для RAG - не просто техническая инновация, а стратегическое улучшение, которое способствует достижению новых высот в сфере интеллектуального поиска и генерации.
Оно сочетает в себе мощь глубокого понимания текста и гибкость современных вычислительных подходов, что делает его незаменимым инструментом для компаний, стремящихся к лидерству в информационных технологиях и обслуживании клиентов. Постоянное развитие моделей, совершенствование промтов и интеграция с кастомизированными решениями обещают еще более высокую эффективность, что делает LLM rerankers одним из важнейших трендов в области искусственного интеллекта и машинного обучения на ближайшие годы. .