В последние годы большие языковые модели (Large Language Models, LLM) стали неотъемлемой частью цифрового мира, оказывая влияние на множество сфер – от автоматизации бизнес-процессов до создания интеллектуальных помощников. Однако одни из ключевых факторов их широкой адаптации – интеграция с внешними системами и инструментами – порождают новые риски безопасности. Особенно это касается взаимодействия через протокол Model Context Protocol (MCP), который был разработан для стандартизации API-взаимодействий между LLM, источниками данных и различными агентскими инструментами. MCP получил широкое признание и быстро вошел в стандартные практики создания комплексных LLM-приложений благодаря своей гибкости и возможности легко интегрировать компоненты. Тем не менее, недавние исследования выявили серьезные пробелы в безопасности, которые могут использоваться злоумышленниками для реализации целого спектра атак, способных нанести существенный урон разработчикам и конечным пользователям.
Основная суть угрозы заключается в том, что протокол MCP позволяет LLM инструментам взаимодействовать друг с другом и с внешними сервисами с минимальными ограничениями. В результате злоумышленники способны заставить модели выполнять опасные операции: запускать вредоносный код, получать несанкционированный доступ к системам разработчиков, похищать учетные данные и даже удаленно управлять ресурсами, подключенными к MCP серверу. Одним из ключевых моментов является то, что сами LLM не наделены встроенными механизмами жесткой проверки безопасности выполняемых команд в рамках MCP, что делает возможным обход традиционных барьеров защиты. Это особенно тревожно в условиях популяризации agentic workflows – систем, которые опираются полностью на автономную работу ИИ, начиная с принятия решений и заканчивая взаимодействием с инфраструктурой. Для борьбы с данными уязвимостями исследователи предложили решение под названием MCPSafetyScanner, представляющее собой комплексный инструмент для аудита безопасности MCP серверов.
MCPSafetyScanner использует множество вспомогательных агентов, которые автоматически генерируют и тестируют потенциально вредоносные сценарии взаимодействия с инструментами и ресурсами MCP. Такой подход позволяет выявлять «адверсариальные» примеры, то есть потенциальные векторы атак, скомбинированные из возможностей MCP. Кроме выявления уязвимостей MCPSafetyScanner осуществляет поиск известных методов их устранения и формирует детальные отчеты по безопасности. Это дает разработчикам возможность своевременно корректировать конфигурации и повышать устойчивость своих систем к внешним воздействиям. Аудитория MCP и связанных с ним решений — это не только инженеры и разработчики, но и специалисты по информационной безопасности, которым крайне важно понимать, что использование MCP требует не только технической грамотности, но и внимательного подхода к защите данных и каналов коммуникации.
Особое внимание стоит уделить тому, что MCP – инструмент открытого стандарта, что несет в себе как преимущества, так и определённые риски. С одной стороны, прозрачность протокола открывает возможности для совместной проверки безопасности и быстрого исправления выявленных проблем. С другой — широкое распространение MCP и отсутствие универсальных средств автоматической защиты делают его привлекательной целью для злоумышленников. Важно подчеркнуть, что серьезность уязвимостей MCP перекликается с общемировыми тенденциями в сфере безопасности ИИ. По мере расширения применения LLM в критически важных сферах – таких как финансы, медицина, государственные службы – вероятность нанесения ущерба от подобных эксплойтов увеличивается многократно.
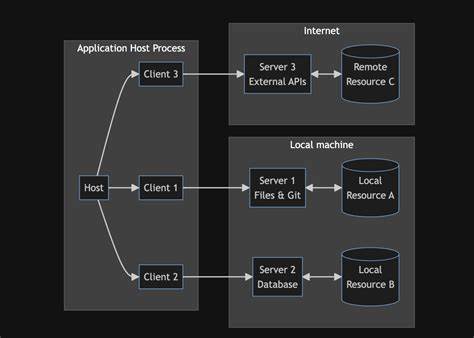
Архитектура MCP включает в себя регистрацию множества инструментов, к которым могут обращаться LLM-модели. Если один из этих инструментов недостаточно изолирован или не имеет должных ограничений, модель может заставить его выполнить действия, выходящие за рамки общего назначения. Это приводит к каталогу потенциальных атак, начиная с исполнения произвольного кода и заканчивая утечками секретной информации. Работа MCPSafetyScanner основана на агентной архитектуре, что является важным шагом вперёд по сравнению с традиционными методами тестирования, где человеческий фактор вносит ограничения по масштабируемости и охвату. Автоматизация позволяет быстрее выявлять слабые места в больших и сложных конфигурациях MCP серверов.
Необходимость в системных решениях для безопасности MCP отражается и в будущем развитии протокола, который, вероятно, будет адаптироваться с учетом рекомендаций по усилению контроля доступа, аутентификации и верификации выполняемых команд в рамках API вызовов. Кроме того, разработчики советуют организациям, использующим MCP, переходить на практики минимизации доверия и внедрять многоуровневую безопасность, включая мониторинг событий, логирование и регулярные аудиты. Интеграция с внешними системами должна сопровождаться строгими правилами проверки входящих и исходящих взаимодействий, а также использования изоляции на уровне процессов и сессий. В целом, проблема безопасности в контексте MCP и LLM – это вызов, который требует объединения усилий исследователей, практиков и стандартных организаций. В долгосрочной перспективе именно такой коллаборативный подход сможет обеспечить надежное развитие технологий генеративного ИИ без ущерба для безопасности и приватности.
Заключая, можно отметить, что инновации в области протоколов и технологий, таких как MCP, безусловно двигают индустрию вперед, предлагая инструменты для создания более гибких и мощных ИИ-систем. Однако каждая новая ступень технического прогресса подразумевает новые вызовы в обеспечении безопасности. Осознание и проактивный аудит уязвимостей, а также внедрение специализированных решений, вроде MCPSafetyScanner, являются ключевыми элементами стратегии защиты, которая позволит безопасно и эффективно использовать большие языковые модели и их возможности в будущем.