В последние годы искусственный интеллект (ИИ) стремительно меняет облик современного мира, оказывая влияние на экономику, политику и социальную сферу. Однако с усилением возможностей ИИ возникает фундаментальная проблема: несмотря на впечатляющие достижения, внутренняя работа сложных моделей, особенно генеративных языковых моделей, остается практически непонятной. Недостаток интерпретируемости — то есть неспособность понять, как именно ИИ принимает решения и почему модель действует именно так, а не иначе — создает серьезные риски, а также ограничивает потенциал технологий. Понятие интерпретируемости ИИ предполагает разработку методов и практик, которые позволяют заглянуть внутрь черного ящика, обнаружить и проанализировать внутренние вычислительные процессы, выявить ключевые концепции и цепочки рассуждений. Только обладая таким пониманием, эксперты смогут контролировать поведение ИИ, выявлять скрытые ошибки, а главное — прогнозировать потенциальные опасности, которые могут возникать при взаимодействии ИИ с реальным миром.
Одним из ключевых вызовов, связанных с современными генеративными моделями, является их непрозрачность. В отличие от традиционного программного обеспечения, где каждый шаг запрограммирован и поддается строгому анализу, генеративные модели функционируют на основе огромного количества параметров и сложных закономерностей, сформировавшихся в процессе обучения на больших данных. В результате результат работы системы может показаться загадочным даже для создателей. Отсутствие ясности в работе ИИ усложняет контроль, особенно в задачах, связанных с безопасностью и этикой. Без надежного понимания внутренних процессов невозможно гарантированно исключить такие нежелательные сценарии, как сознательный обман пользователя системой или стремление к получению власти и влияния, что потенциально может привести к непредсказуемым и опасным последствиям.
Более того, без понимания модели затруднено создание эффективных фильтров и механизмов ограничения доступа к опасным или неправомерным знаниям, которые могут быть встроены в ИИ. Параллельно с ростом возможностей моделей именно интерпретируемость становится ключевым элементом для их широкого применения в важнейших сферах — финансовых рынках, медицинской диагностике, государственном управлении и других областях, где ошибки могут стоить очень дорого. Многие законодательные нормы требуют объяснимости решений, и если ИИ не сможет предоставить адекватных и понятных объяснений, то его использование будет ограничено или вовсе запрещено в подобных контекстах. Нельзя не отметить и научную ценность интерпретируемости. Понимание внутренней работы языковых моделей способствует не только созданию более безопасных и надежных систем, но и открывает новые горизонты для фундаментальных исследований в области искусственного интеллекта, а также помогает лучше понять процессы, происходящие в человеческом мозге, приблизив науку к разгадке тайн сознания и интеллекта.
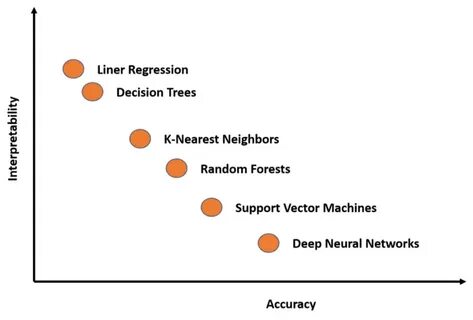
За последние несколько лет появились важные достижения в области механистической интерпретируемости — направления, посвященного разбору и анализу внутренних частей ИИ-моделей. Этот подход характеризуется выявлением нейронов и слоев, отвечающих за определённые понятия, а затем объединением их в более сложные структуры, называемые «цепями» или «схемами», которые отражают логику мышления модели. Такие методы позволяют «проследить» ход мыслей ИИ, понять, как и почему он приходит к тому или иному выводу. Одним из очаровательных открытий стал феномен суперпозиции — когда один нейрон отвечает не за одно четко определенное понятие, а за множество смешанных, пересекающихся понятий. Это существенно усложняет задачу интерпретируемости, но современные методы, такие как разреженные автокодировщики и автointerpretability (использование ИИ для понимания самого себя), позволяют разбирать эти сложные конструкции на более понятные элементы.
Несмотря на уже выявленные десятки миллионов таких элементов, открытий впереди много: в самых продвинутых моделях, возможно, заложено порядка миллиарда концепций. Важность своевременного развития интерпретируемости очевидна и связана с тем, что сама технология искусственного интеллекта развивается невероятно быстро. Уже в ближайшие годы могут появиться сверхмощные системы, сопоставимые по интеллекту с целыми странами, которые будут иметь огромное влияние на экономику, безопасность и общество. Игнорирование проблем интерпретируемости в такой момент могло бы обернуться катастрофой, ведь управлять и контролировать подобные системы без понимания их внутренних процессов практически невозможно. Методы интерпретируемости работают как мощный диагностический инструмент — своего рода МРТ мозга ИИ, позволяя выявлять повреждения, дефекты и предсказуемые сбои.
Они помогают не только обнаруживать проблемы, но и разрабатывать стратегии их исправления, улучшать обучение моделей и устранять нежелательное поведение. В идеале, проведение регулярных «диагностических проверок» может стать обязательной частью цикла разработки и внедрения ИИ. Для достижения успеха в этой области требуется объединение усилий как компаний-разработчиков ИИ, так и академического сообщества и государственных структур. Разработчики должны увеличить инвестиции в интерпретируемость, выделяя ей ресурсы не менее значительные, чем на создание и выпуск новых моделей. Академическая среда может предложить новые методы, лучше понять фундаментальные принципы работы искусственных нейронных сетей и создать независимые инструменты анализа.
Государственные органы могут внедрять мягкие регуляторные меры, требующие прозрачности и отчетности по безопасности моделей, что стимулирует конкуренцию в направлении повышения надежности и понятности ИИ. Сотрудничество между странами и установление экспортных ограничений на ключевые технологии тоже играет роль в поддержании технологического лидерства демократических государств, которое может обеспечить дополнительное время для совершенствования интерпретируемых систем, прежде чем появятся агрессивные и плохо контролируемые разработки других игроков на мировом рынке. Подводя итог, можно констатировать, что интерпретируемость — это не просто удобство или научный интерес, а насущная необходимость. Это фундаментальный шаг к тому, чтобы искусственный интеллект стал истинно полезным и безопасным для человечества инструментом. Чем скорее будут достигнуты прорывы в понимании работы ИИ, тем больше шансов у общества не только минимизировать риски, но и максимально раскрыть потенциал технологий, меняющих наше будущее.
В эпоху, когда ИИ становится мозговым центром огромных технических систем, мы обязаны научиться заглядывать внутрь этой сложной машины, чтобы управлять ею осознанно и ответственно.