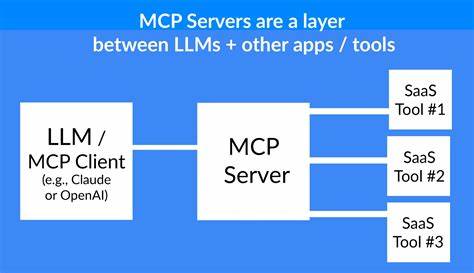
В последние годы активно развивается область искусственного интеллекта, и с ней связана новая парадигма взаимодействия – Model Context Protocol, или MCP. Эта технология кардинально меняет способ, которым AI-приложения взаимодействуют с внешними системами, такими как базы данных, API и файловые системы через специализированные серверы. Рост популярности MCP-серверов в начале 2025 года продемонстрировал важность понимания особенностей их производительности и необходимости адаптированных подходов к оптимизации. В отличие от традиционных веб-сервисов или API, MCP-серверы сталкиваются с принципиально иными нагрузками. Если в классических системах запросы генерируются людьми, то здесь запросы поступают от AI-моделей, способных создавать сотни и даже тысячи параллельных запросов в рамках одного диалога.
Такой масштаб параллелизма и объём обрабатываемых данных приводят к новым узким местам в производительности, которые невозможно эффективно решить традиционными методами. Одним из ключевых отличий является поведение AI с его уникальными требованиями к задержкам и объёму данных в контексте. Модель может активно запрашивать несколько параллельных операций – от базы данных до файловых систем и внешних API – формируя сложные цепочки обработки. В итоге становится критически важным глубокое понимание деталей работы MCP с токенами. Токенизация оказывает огромное влияние на работу MCP-серверов.
Для обычных веб-сервисов размер ответа влияет на скорость передачи по сети, но в случае MCP каждый символ и каждый токен данных оказывают прямое влияние на контекстное окно AI модели. Современные модели способны обрабатывать десятки и сотни тысяч токенов, однако даже большой контекст быстро заполняется при условии множества последовательных запросов к серверу. Нагрузка на контекст увеличивается с каждым ответом от сервера, что в конечном итоге приводит к необходимости забывать часть предыдущей информации. Это негативно сказывается на качестве взаимодействия с моделью и ведёт к ухудшению результатов работы AI, снижая его эффективность. Если оптимизировать ответы MCP, уменьшая размер возвращаемых данных, можно значительно продлить время «жизни» сессии и повысить общую производительность.
Одной из наиболее удачных стратегий является минимизация JSON-ответов. JSON является удобным форматом для структурирования данных, но он создает значительные накладные расходы в плане размера и токенов. Часто ответы могут содержать множество избыточных полей, не имеющих практической значимости для непосредственно решаемой задачи. Сокращение и фильтрация возвращаемых данных позволяет уменьшить нагрузку на сеть и контекст модели. Примером служит ситуация с возвратом адресных данных.
Стандартный JSON-объект часто содержит десятки полей, включая временные метки, координаты и другие метаданные, которые не всегда необходимы AI. Если заменить их компактным форматом, включающим лишь идентификатор, объединённый адрес и пару флагов состояния, можно сэкономить до 60-80% размера ответа. Такой подход может реализовываться как динамический выбор полей, запрашиваемых клиентом, или создание специализированных конечных точек с заранее оптимизированными наборами данных. Еще более радикальный подход — отказ от JSON в пользу простого текстового формата. Естественный язык и текстовые списки прекрасно воспринимаются современными языковыми моделями, при этом существенно сокращается токенизация за счет исключения структурных элементов JSON, таких как скобки, кавычки, запятые и ключи.
Этот метод отлично подходит для файловых списков, логов, табличных данных или статусных отчётов. Однако стоит помнить, что текстовый формат снижает машиночитаемость данных, что может усложнить автоматическую обработку на последующих этапах. Поэтому применять его рекомендуется только там, где такой компромисс оправдан и понятно документирован. Не менее важным элементом оптимизации является влияние определений инструментов MCP. В отличие от традиционных API, описания инструментов и их схемы должны обрабатываться как часть контекста AI.
Это значит, что каждый параметр, описание функции и пример использования не только увеличивают размер запроса, но и уменьшают доступный контекст для реальной работы с данными. Чем сложнее и детальнее схема инструмента, тем больше токенов она поглощает. Этому способствует наличие вложенных объектов, валидаций, многоуровневой структуры и подробных примеров. Многие крупные корпоративные решения используют до 20 отдельных инструментов с суммарной нагрузкой в десятки тысяч токенов на одни только определения. Для уменьшения данного воздействия требуется максимально лаконичное и понятное описание инструментов.
Практика показывает, что отказ от избыточных повторений, сокращение примеров и вынос сложных подробностей во внешнюю документацию значительно снижает общую нагрузку. Кроме того, существует возможность динамического подключения инструментов в зависимости от тематики диалога, что позволяет уменьшать количество одновременно загружаемых инструментальных описаний. Ещё один критический фактор производительности — географическое положение серверов. MCP-сервера лучше всего показывают себя при размещении в непосредственной близости к инфраструктуре AI провайдеров. К примеру, сервера, расположенные в дата-центрах США, демонстрируют значительно меньшую задержку при работе с моделями Claude, чем их аналоги, размещённые в Европе или Азии.
Задержка играет решающую роль, поскольку AI-модели часто выполняют цепочки последовательных вызовов, где каждый новый запрос зависит от предыдущего ответа. Накопление даже небольших задержек приводит к значительному замедлению реакции и ухудшению пользовательского опыта. С учётом глобального распространения AI-сервисов и расширения их инфраструктуры серверы MCP должны располагаться в нескольких регионах. Это требует организации географического балансирования нагрузки, репликации данных и синхронизации между серверами. Несмотря на дополнительную сложность, такие меры позволяют добиться максимально возможной скорости и эффективности при обслуживании глобальной аудитории.
Все рассмотренные аспекты рисуют яркую картину новой парадигмы оптимизации MCP серверов. Традиционные подходы, как кэширование и балансировка нагрузки, остаются важными, но их недостаточно для AI-ориентированных нагрузок. Необходимо учитывать влияние токенов на контекст, тщательно отбирать данные, использовать эффективные форматы ответов, оптимизировать инструментарий и размещать серверы ближе к AI-инфраструктуре. Этот комплекс мер позволяет создавать высокопроизводительные, масштабируемые и экономически выгодные MCP решения. В условиях быстрорастущего спроса на AI-сервисы и расширения рабочих сценариев роль правильной оптимизации становится всё более значимой.
Крупные агентства, специализирующиеся на веб-производительности, активно исследуют данные направления и предлагают помощь в корректной настройке MCP серверов. Внедрение актуальных методик позволяет не только повысить скорость работы, но и улучшить качество взаимодействия с AI, что критично для успеха современных и перспективных приложений. Таким образом, оптимизация MCP серверов — это не просто техническая задача, а целая стратегическая инициатива, охватывающая сразу несколько уровней архитектуры и взаимодействия. Фокусируясь на грамотном управлении токенами, минимизации передаваемой информации и географических особенностях, можно значительно увеличить отдачу от внедрения MCP и обеспечить конкурентные преимущества в сфере AI-технологий.