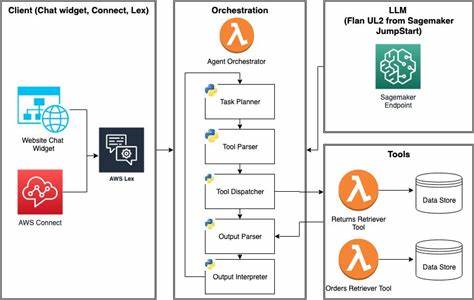
В наш век цифровизации и стремительно развивающихся технологий искусственный интеллект (ИИ) всё активнее проникает в разные сферы человеческой деятельности. Среди инновационных решений, сочетающих традиционные компьютерные технологии с возможностями ИИ, особое место занимает идея файловой системы, полностью контролируемой языковой моделью искусственного интеллекта, или LLM (Large Language Model). Данная концепция открывает новые горизонты в области управления и генерации данных, существенно меняя представление о хранении информации и взаимодействии с файлами. Файловая система, подкреплённая языковой моделью, или LLMFS, принципиально отличается от классических систем, которые опираются на жёсткое хранение и физическое обращение к носителям. В своей основе LLMFS реализована с помощью технологий FUSE (Filesystem in Userspace), что позволяет интегрировать файловую систему в пользовательское пространство операционной системы без необходимости глубоких модификаций ядра.
Все операции с файлами — чтение, запись, создание или удаление — делегируются вызовам к языковой модели искусственного интеллекта, которая обрабатывает запросы, генерирует содержимое файлов и контролирует доступ. Ключевая особенность такой системы заключается в том, что данные не хранятся на диске в изначальном виде. Вместо этого все изменения и операции записываются в историю взаимодействий, которая становится контекстом для ИИ. Благодаря этому языковая модель способна помнить последовательность изменений, понимать содержание файлов и синтезировать необходимую информацию на лету. Это решает проблему избыточного хранения, освобождает пространство на диске и обеспечивает возможность динамического обновления контента.
Взаимодействие с таким файловым пространством происходит через стандартные инструменты операционной системы — команды, программы, API. При обращении к файлу, к примеру, при чтении, система использует промпт, сформированный на основе текущей системы и истории действий, чтобы запросить у модели данные. Модель возвращает содержимое файла в формате JSON, строго следуя установленному протоколу, что позволяет корректно интерпретировать возвращаемую информацию и обрабатывать возможные ошибки или запреты. Безопасность и контроль доступа в LLMFS реализуются посредством внутренней логики языковой модели. Система способна самостоятельно запретить критичные операции, например, запись в системные файлы или выполнение потенциально опасных скриптов, возвращая стандартные коды ошибок UNIX, такие как EACCES для отказа в доступе.
Такой подход упрощает поддержку политики безопасности и снижает риски повреждения системы. Реализация LLMFS, как правило, сопровождается значительными задержками по сравнению с традиционными тысячами операций ввода-вывода в секунду. Это связано с тем, что каждый запрос к файловой системе подразумевает отправку и получение данных от внешнего сервиса ИИ, что занимает сотни миллисекунд. Тем не менее, стоит отметить, что текущие достижения в области масштабирования и оптимизации языковых моделей позволяют значительно снизить эти задержки для определённых категорий задач. Архитектурно, примером реализации служит программа, использующая языковую модель GPT-4 от OpenAI, на которой основан специализированный клиент, обрабатывающий системные вызовы через интерфейс FUSE.
В ней применяется единая очередность исполнения запросов, гарантируя последовательное и непротиворечивое состояние виртуальных файлов. Благодаря этому можно точно воспроизвести содержимое документа, даже если оно менялось неоднократно в течение сессии взаимодействия. Идея генерации и управления файлами с помощью ИИ открывает большие возможности в сфере автоматизации и творческого программирования. Представьте файловую систему, которая сама пишет код по запросу пользователя, тестирует и оценивает его корректность в реальном времени. Проекты, пробующие подобную логику, уже демонстрируют, что границы между простым хранилищем данных и интеллектуальной исходной платформой стираются.
При этом важно учитывать и потенциальные сложности, связанные с гарантией целостности и надёжности данных. Поскольку информация хранится в памяти и оперативно генерируется, без физического резервного копирования она уязвима перед потерей из-за сбоев или непредвиденных ошибок. Решением может стать гибридный подход, когда наиболее важные файлы дублируются на традиционных носителях, а вспомогательные — обрабатываются через LLM. Текущие исследования также рассматривают вопросы масштабируемости модели и возможностей интеграции с существующими файловыми сервисами и облачными решениями. Прямая сериализация объектов для межкомпонентного взаимодействия, расширение протокола запросов и более продвинутое управление состоянием позволяют ожидать в будущем появление полноценной экосистемы, где ИИ не только управляет файлами, но и оптимизирует весь жизненный цикл данных.






![Induction lamps: fluorescent lighting's final form [video]](/images/34D3E574-1CA0-4A7F-B411-06C0B21182BB)
