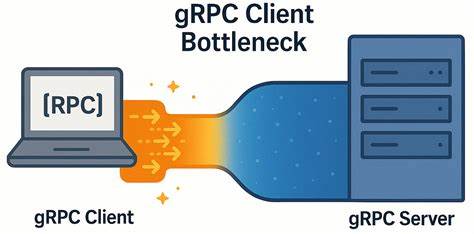
gRPC давно зарекомендовал себя как мощный и надёжный протокол для взаимодействия микросервисов и клиентских приложений с серверными системами. Он построен поверх HTTP/2, что даёт всем пользователям преимущества многопоточности и мультиплексирования запросов по одному TCP-соединению. Однако в современных условиях использования высокоскоростных и низколатентных сетей могут неожиданно проявляться специфические проблемы производительности именно на стороне клиента. Такие узкие места серьёзно влияют на пропускную способность и увеличивают задержки в системах с высокой нагрузкой, даже если сеть и сервер обеспечивают отличные показатели. В результате разработчики и системные администраторы сталкиваются с ситуацией, когда уменьшая число серверных узлов — то есть пытаясь оптимизировать инфраструктуру и использовать меньше ресурсов — проницаемость нагрузки ухудшается, а клиентские задержки растут.
Погружаясь глубже, специалисты YDB провели исследование и выявили истинную корень проблемы, которая обнаруживается именно в клиентской реализации gRPC. На примере простого микро-бенчмарка, написанного на C++, авторы показали, что даже при минимальной сложности сам клиент становится узким местом, ограничивающим возможность горизонтального масштабирования и увеличения производительности. Важным наблюдением стало то, что при использовании стандартных настроек многие каналы gRPC оказываются обременены одним-единственным TCP-соединением. В этом случае HTTP/2 обеспечивает мультиплексирование многих потоков (RPC) по одному соединению, что на первый взгляд кажется рациональным решением — меньше управляющих соединений, меньше накладных расходов. Но при низкой задержке сети и высокой частоте запросов возникает внутреннее ограничение – максимальное число конкурирующих потоков на одном TCP-соединении.
По умолчанию это число ограничено значением около ста потоков, и при достижении этого лимита дополнительные запросы ставятся в очередь. Такая очередь формируется на клиентской стороне, что замедляет отправку запросов и вызывает накапливающуюся задержку. Проблема осложняется тем, что в нестандартных сценариях, например при сжатом кластере, серверные мощности не успевают принимать больше запросов, клиенты простаивают, но их задержка растёт. Это противоречит привычным представлениям о производительности сетевых сервисов и провоцирует поиск нестандартных решений. Для изучения поведения была реализована микрозадача - ping benchmarking сервер и клиент, которые обменивались короткими сообщениями без полезной нагрузки, что позволило минимизировать влияние бизнес-логики и сетевых факторов на измерения.
Тесты проводились на реальных физических машинах с двухпроцессорной архитектурой Intel Xeon Gold и подключением по 50 гигабитному каналу с минимальными задержками в сотни микросекунд. Эксперименты с увеличением параллельности RPC показали, что увеличение количества одновременных запросов приводит к нелинейному росту пропускной способности, а задержка начинает расти практически пропорционально числу подключений. Несмотря на мощь серверной платформы и отличные характеристики сети, результаты оставались далеки от идеала, демонстрируя подавляющее влияние клиентской части. Самым неожиданным оказалось то, что все клиентские gRPC-каналы по умолчанию использовали одно и то же TCP-соединение, что приводило к накоплению очереди внутри клиента. Логирование вызовов и анализ сетевого трафика показали, что после получения ответа от сервера между последовательными запросами возникает пауза длительностью до 200 микросекунд – именно в этот промежуток времени происходит ожидание освобождения ресурсов в клиентском стеке TCP и gRPC.
Для устранения такого эффекта были протестированы разные подходы, в том числе использование отдельных каналов gRPC для каждого рабочего процесса клиента и объединение каналов в пулы с различными параметрами. Изначально оба подхода казались альтернативными решениями. Но в ходе экспериментов выяснилось, что под разными аргументами к каналам создаются уникальные TCP-соединения, что решает проблему очередей и значительно снижает задержки. Именно настройка канала с уникальными параметрами в сочетании с распределением нагрузки между множеством TCP-соединений стала ключевым фактором улучшения производительности. Также эффективным решением оказалось включение использования локального пула сабканалов GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL, который позволяет элегантно масштабировать клиентскую часть без сложных ручных манипуляций.
В результате новая архитектура клиента демонстрировала в шесть раз выше пропускную способность по сравнению с одиночным соединением и более плавный рост латентности при увеличении числа одновременных запросов. Это позволило добиться действительно высокой скорости обмена сообщениями и снизить общие задержки, что крайне важно для интерактивных систем и сервисов реального времени. Особый интерес представляло сравнение показателей в условиях реальной сети с задержкой около 5 миллисекунд — ситуация, характерная для распределённых дата-центров или публичных интернет-сервисов. В таких условиях влияние внутреннего ограничения клиента было минимально заметным, поскольку сетевые задержки доминировали над внутренними задержками gRPC. Значит, указанное узкое место в клиенте gRPC является наиболее актуальным именно в среде с сетями очень низкой задержки и высоким качеством соединения, где внутренняя оптимизация кода клиента становится критическим фактором.
Итогом исследования стало понимание того, что официальные рекомендации gRPC по разделению нагрузок между каналами являются частями единого решения, которое нужно применять комплексно. Создание уникальных каналов для каждого рабочего процесса с правильными параметрами конфигурации и применение локального пула сабканалов обеспечивают значительный выигрыш по производительности и стабильности. Это важное замечание для разработчиков распределённых систем и тех, кто строит высокопроизводительные сервисы с использованием gRPC в инфраструктуре с низкой латентностью. Кроме того, статья приглашает сообщество к дальнейшим экспериментам и поиску новых способов оптимизации, что подтверждает зрелость и открытость технологии. Для многих предприятий и приложений, где низкая задержка и высокая пропускная способность критичны — будь то финансовые рынки, гейминговые сервисы или системы мгновенной аналитики — понимание и устранение подобных клиентских ограничений приведёт к ощутимому улучшению пользовательского опыта и эффективности работы.
Таким образом, данное исследование раскрывает малоизвестный, но важный аспект использования gRPC в современных условиях, помогает избежать ложных предположений о возможностях масштабирования и указывает путь к реальным улучшениям. Использование нескольких специализированных каналов и оптимизированных пулов для уменьшения клиентских задержек становится обязательной практикой при проектировании высоко нагруженных систем в высокоскоростных и малозадерживающих сетях. Это открывает новые горизонты для эффективной работы распределённых баз данных, API-сервисов и микросервисных архитектур, где каждая миллисекунда на счету.