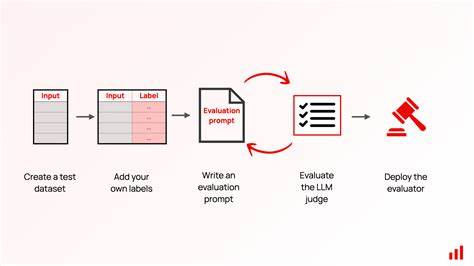
Современные технологии больших языковых моделей (LLM) продолжают стремительно развиваться, вливаясь в повседневную жизнь и бизнес-процессы с беспрецедентной скоростью. Вместе с ростом их мощи возрастает и необходимость контролировать качество их работы. Одним из революционных подходов в данной области становится использование самих LLM в качестве автоматизированных судей — инструмента, который не только оценивает результаты, но и помогает выявлять ошибки и дополнительные качества, влияющие на эффективность ИИ-приложений. Введение такой системы позволяет не просто ускорить процесс оценки, но и делать это с высокой степенью объективности и точности. В основе концепции LLM-as-a-Judge лежит идея автоматизации оценки выходных данных моделей с применением специализированных моделей-судей.
Такой подход выводит на новый уровень качество анализа, делая его более последовательным и менее подверженным человеческим субъективным ошибкам. Эти судьи способны не только выставлять оценку, но и подробно объяснять ее причины, а также выявлять проблемные места, что способствует улучшению итогового результата. Одним из ключевых вызовов, с которыми сталкивается LLM-система в роли судьи, является необходимость нейтрализовать распространённые виды смещений, таких как избыточная многословность, чрезмерная уверенность в ответах и влияние порядка подачи информации (позицонное смещение). Для противодействия этим эффектам применяются специальные техники, включающие использование Chain-of-Thought размышлений — пошагового анализа логики ответа — и оценку на уровне отдельных токенов, что позволяет более тонко выявлять и исправлять ошибки. Кроме того, значительную роль играет метод парных сравнений, когда судье предлагаются два варианта ответа, и она выбирает более качественный.
Это повышает точность оценки и помогает разработчикам грамотно направлять доработки модели. Создание собственной системы LLM-as-a-Judge требует структурированного подхода и глубокого понимания особенностей моделей. Практические рекомендации и примеры кода помогают специалистам быстро включиться в процесс, избегая распространённых подводных камней. Более того, такая система становится фундаментом для построения надежных ИИ-приложений, способных автономно отслеживать и повышать качество своих решений. Использование LLM в качестве судей также существенно сокращает затраты времени и усилий, обеспечивает стандартизированный подход к контролю качества и способствует развитию более продвинутых решений.
Комбинация автоматизации и интеллектуального анализа позволяет создавать системы, которые не просто выполняют задачи, а постоянно учатся и адаптируются, повышая эффективность в различных сферах — от образования и науки до бизнеса и информационных технологий. Рынок ИИ переживает значительный рост и конкуренцию, поэтому надежность и качество продуктов становятся критическими факторами успеха. Внедрение LLM-as-a-Judge помогает компаниям закрепиться в лидирующих позициях, предлагая продукт, построенный на основе строгой и объективной оценки работы модели. Таким образом, развитие и освоение методик «судейства» больших языковых моделей становится новой вехой в истории искусственного интеллекта. Важность этого процесса невозможно переоценить, так как от него зависит не только точность и эффективность конкретных приложений, но и общее развитие индустрии ИИ.
Пользователи получают более качественные, надежные и интуитивно понятные решения, что поднимает уровень доверия к технологиям и стимулирует их активное внедрение. В заключение, LLM-as-a-Judge представляет собой мощный инструмент для улучшения качества оценки и наблюдения за работой ИИ, обеспечивая беспрецедентный уровень точности и автоматизации. Освоение этого подхода открывает новые горизонты в создании надежных, адаптивных и интеллектуальных систем, отвечающих современным требованиям и ожиданиям. Опираясь на передовые практики и технологии проведения оценки, разработчики могут создавать более совершенные решения, которые станут неотъемлемой частью будущего цифрового мира.

![Microsoft 9000 layoffs not performance-based, largely targeting middle managers [video]](/images/1437CDD1-12FD-49BD-BBDF-987576291C47)