Развитие искусственного интеллекта привело к появлению больших языковых моделей (БЯМ), таких как GPT-2, GPT-3 и далее, которые революционизировали обработку естественного языка. Однако с увеличением размеров и возможностей таких моделей появляются серьезные проблемы, связанные с высокой вычислительной нагрузкой и значительным энергопотреблением. Решение этих вопросов становится приоритетной задачей в мире ИИ и аппаратного дизайна. Одним из перспективных направлений выступает использование аналоговых вычислений непосредственно в памяти (in-memory computing, IMC) с применением новых архитектур механизма внимания, что обеспечивает не только ускорение обработки, но и значительную экономию энергии. Механизм внимания, лежащий в основе трансформеров, отвечает за установление взаимосвязей между различными элементами входной последовательности.
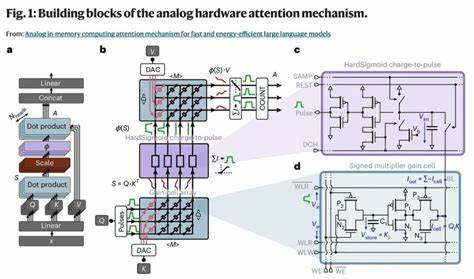
В классической реализации этот процесс требует многочисленных операций перемножения и суммирования в цифровом формате, что ведет к высоким задержкам и энергозатратам, особенно при работе с длинными последовательностями токенов. Традиционно для хранения ключей (keys) и значений (values) в механизме внимания используется большая кольцевая память KV cache, которая при каждой генерации нового токена загружается из основной памяти в SRAM - статическую память с произвольным доступом. Именно эта операция становится узким местом при масштабировании моделей. Аналоговая встраиваемая вычислительная память, представляющая собой специализированные схемы с ячейками памяти - так называемыми gain cells - предлагает уникальное сочетание высокой плотности хранения данных и возможности выполнения параллельных умножений прямо в точке хранения. Такие устройства основаны на зарядовых конденсаторах и полевых транзисторах из оксидных полупроводников, способных удерживать заряд и преобразовывать его в токовой сигнал, пропорциональный сохранённому значению.
В отличие от традиционной DRAM и SRAM, gain cells обеспечивают быстрое программирование, длительное удержание состояния даже в отсутствии питания (особенно на базе OSFET) и многократный уровень хранения, что повышает плотность и функциональность. Важной особенностью предложенной архитектуры является проведение ключевых операций механизма внимания по вычислению двух последовательных скалярных произведений полностью в аналоговой доменной зоне. Запросы (queries) кодируются в импульсно-широтной модуляции (PWM) и подаются на первый массив gain cell для умножения на сохранённые ключи. Результирующий ток интегрируется специализированной схемой charge-to-pulse, которая выполняет аналог функции активации, реализуя HardSigmoid, заменяющую традиционный softmax. Затем полученный аналоговый выход подается как вход на второй массив для перемножения с сохранёнными значениями (values), а итоговый результат цифровым считыванием и подсчетом импульсов передается для дальнейшей обработки.
Реализация вычислений в аналоговом формате позволяет существенно снизить энергозатраты на преобразование аналоговых сигналов в цифровые, что является традиционным потребителем энергии в подобных системах. Аналоговые цепи charge-to-pulse и их интеграция в модульную архитектуру обеспечивают масштабируемость с поддержкой множества блоков (субтайлов), необходимые для работы с высокими размерностями эмбеддингов и длинными окнами внимания. Естественным вопросом при такой архитектуре является нетривиальная адаптация предобученных языковых моделей к особенностям нестандартного вычислительного механизма. В данном случае аналитически выраженная нелинейность умножения в gain cells, квантование входных и выходных сигналов с ограниченным уровнем точности, а также замена softmax на HardSigmoid требуют разработки специализированных алгоритмов переноса и дообучения моделей. Используя двухэтапный подход сначала с адаптацией промежуточной модели с линейным умножением, а затем с применением алгоритмов масштабирования входных данных и параметров слоев, разработчики достигли производительности, сопоставимой с GPT-2 без необходимости тренировки модели с нуля, существенно экономя ресурсы.
Выходные результаты демонстрируют не только высокую точность на различных бенчмарках, включая задачи вопросов-ответов, понимания контекста и генерации текста, но и удивительный прогресс в плане производительности. Аналоговая архитектура в сравнении с современными потребительскими и серверными GPU показывает сокращение латентности выполнения операций внимания на два порядка, а энергопотребление снижается до 4-5 порядков, что открывает перспективы для внедрения больших языковых моделей в устройствах с ограниченным питанием, таких как мобильные гаджеты и встроенные системы. Планируемое использование тонкопленочных транзисторов на базе оксидных полупроводников способствует дальнейшему повышению плотности элементов памяти и трехмерной интеграции, позволяя компактно размещать многослойные структуры gain cells и сопутствующие аналоговые и цифровые блоки. Такая многоуровневая реализация обещает значительно уменьшить занимаемую площадь и повысить масштабируемость решений для всех слоев трансформера. Изучение утечек заряда и динамики сохранения значения в конденсаторах становится важной составляющей при проектировании.
Несмотря на то, что коэффициенты утечки в CMOS-based gain cells дают время удержания порядка миллисекунд, при применении OSFET технологии сохранение может достигать секунд, минимизируя необходимость частого обновления памяти во время обработки длинных последовательностей. Внедрение механизма скользящего окна внимания (sliding window attention) обеспечивает управление размером KV кеша без экспоненциального роста требований к памяти, что особенно актуально для длинных текстов. Этот подход совместим с аппаратной реализацией и обеспечивает баланс между полнотой внимания и ресурсными ограничениями. Переход к аналоговому in-memory computing и аппаратно-алгоритмическое совместное проектирование - уникальный шаг к устранению главных барьеров в производительности больших языковых моделей. Он открывает путь к быстродействующим, энергоэффективным генеративным трансформерам, которые смогут использоваться в широком спектре приложений, от облачных сервисов до распределённых систем и устройств Интернета вещей.
Наряду с аппаратными инновациями, развивается также программное обеспечение: методы тонкой настройки моделей с учетом аппаратных особенностей, алгоритмы квантования и адаптации нелинейностей, что обеспечивает сохранение эмпирической точности и надежности при переносе сложных моделей на новое железо. При взгляде в будущее становится очевидной необходимость интеграции анализа эффективности всех компонентов трансформера: внимания, линейных слоев, нелинейных функций активаций и нормализаций, а также стратегии распределения вычислений между цифровыми, аналого-цифровыми и аналоговыми блоками для максимальной оптимизации ресурсов. Таким образом, запуск масштабируемых, высокопроизводительных, но энергоэффективных больших языковых моделей становится реальностью благодаря развитию аналоговых вычислительных архитектур в памяти. Такие инновации выводят искусственный интеллект на новый уровень, делая его доступным и выгодным для массового применения, при этом снижая углеродный след вычислительных центров и расширяя границы возможностей современных ИИ-технологий. .