В современном мире стремительного развития искусственного интеллекта на передний план выходят инновационные технологии, способные кардинально изменить подход к обработке и использованию информации. Одной из таких технологий является Retrieval-Augmented Generation (RAG) — концепция, объединяющая методы поиска релевантной информации в больших объемах данных и генерацию ответов с использованием нейросетевых моделей. Несмотря на очевидный потенциал RAG, разработчикам, работающим с этими системами, приходится сталкиваться с рядом серьезных технических и организационных вызовов. Понимание опыта и проблем, которые возникают в процессе внедрения RAG, критично для дальнейшего совершенствования инструментов и повышения эффективности разработок. Многие специалисты отмечают, что основной задачей при создании AI-систем с механизмом извлечения знаний из документов или других источников данных становится именно налаживание эффективного взаимодействия между компонентами.
Источники данных могут быть разнообразными — от PDF файлов и HTML страниц до плохо структурированных текстовых документов. Каждый из этих форматов накладывает свои ограничения и требует индивидуального подхода к обработке. Проблематика хранения и поиска информации в таких разнородных данных становится особенно острой, когда необходимо быстро и точно извлечь релевантный контент для последующей генерации. Важным элементом архитектуры RAG-системы является использование векторных баз данных, таких как Pinecone, Weaviate или Qdrant. Эти технологии позволяют преобразовывать текстовую информацию в векторные представления, что упрощает поиск смыслового сходства и ускоряет процедуру возврата релевантных фрагментов.
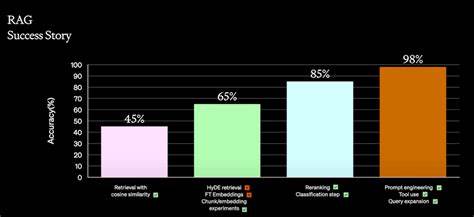
Однако интеграция подобных баз данных в существующие конвейеры разработки часто вызывает сложности. Во-первых, нужно правильно определить стратегию разбиения исходных текстов на осмысленные куски — процесс, называемый chunking. Его качество напрямую влияет на точность поиска и качество генерации конечного ответа. Адекватное chunking требует глубокого понимания структуры и контекста документов, что делает процесс не всегда тривиальным. После разбиения возникает следующий важный этап — эмбеддинг — преобразование текстовых фрагментов в векторные представления с помощью моделей машинного обучения.
Выбор правильной модели и параметров эмбеддинга играет ключевую роль в дальнейшем успехе системы. Неправильно подобранные параметры могут привести к потере смысловой информации и ухудшению результатов поиска. Третьим, не менее важным аспектом, является эффективное хранение и организация данных в векторной базе. Оптимальная индексация, масштабируемость и производительность базы данных определяют скорость работы всей RAG-системы. Разработчики часто сталкиваются с необходимостью тонкой настройки и тестирования различных конфигураций, чтобы достичь баланса между скоростью и качеством.
Также важный фактор — это поддержка и интеграция всех элементов конвейера, включающего chunking, embedding, хранение и поиск, а также генерацию ответов с помощью языковых моделей. Комплексность такой системы повышает вероятность возникновения ошибок и затрудняет отладку. Каждый из этапов может влиять на результат, поэтому разработчикам важно иметь возможность легко мониторить и анализировать работу каждого компонента. С точки зрения работы с документами разработчики особенно выделяют проблемы, связанные с неоднородностью и неструктурированностью исходных данных. PDF-файлы, веб-страницы и прочие источники часто содержат лишнюю информацию, скрытые символы или неровную структуру, что осложняет их автоматическую обработку.
Возможность быстро и точно выделять значимые для поиска части текста существенно упрощает процесс разработки RAG-системы. Еще одним аспектом сложности является необходимость учитывать контекст и доменную специфику. Общие подходы к chunking и embedding могут не сработать одинаково хорошо для разных предметных областей, будь то медицина, финансы или техническая документация. Всестороннее понимание специфичных требований и особенностей данных позволяет повысить точность и полезность создаваемых систем. Ряд опрошенных специалистов мечтают о появлении универсальных инструментов, способных интегрировать весь цикл работы с документами и поиском — от автоматического извлечения и разбиения текста до тонкой настройки эмбеддингов и масштабируемой работы с векторными базами.
Такие решения упростили бы разработку и сократили временные затраты, снизив порог входа для новых игроков в области AI. Кроме того, востребованными являются инструменты с расширенными возможностями визуализации и взаимодействия, позволяющие наглядно видеть, как именно обрабатываются данные и какие ошибки или узкие места существуют в системе. В целом, опыт работы с системами Retrieval-Augmented Generation демонстрирует, что это довольно сложное, но чрезвычайно перспективное направление. С каждым днем появляются новые библиотеки, платформы и подходы, которые шаг за шагом упрощают создание и поддержку таких решений. Тем не менее для полного раскрытия потенциала RAG требуются дальнейшие совместные усилия сообщества разработчиков, исследователей и компаний.
Создание стандартизированных методик chunking, улучшение моделей эмбеддинга, оптимизация векторных баз данных и развитие удобных средств мониторинга — все это ключевые направления развития. В результате пользователи смогут рассчитывать на более быстрые, точные и надежные AI-системы, способные извлекать знания из самых разнообразных источников без сложностей и компромиссов. Важно отметить, что обратная связь от разработчиков играет решающую роль в эволюции этих технологий. Понимание реальных проблем и пожеланий позволяет производителям программных решений создавать продукты, максимально ориентированные на потребности практиков. Опыт сообщества становится фундаментом для внедрения инноваций, которые меняют бизнес-процессы и качество повседневной жизни.
Таким образом, сейчас — уникальный период, когда каждый, кто занимается разработкой AI-систем с использованием RAG, может внести свой вклад в формирование будущего искусственного интеллекта. Чем более эффективными и удобными станут инструменты сегодня, тем быстрее человечество сможет воспользоваться всеми преимуществами умных технологий завтра.