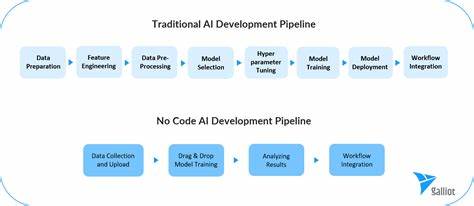
В последние годы no-code и low-code инструменты стремительно изменили подход к анализу данных и построению моделей машинного обучения. Они превратились из нишевых решений в важный элемент современного стека технологий, предоставляя бизнес-аналитикам, маркетологам, продакт-менеджерам и начинающим специалистам возможность самостоятельно исследовать данные, создавать модели и визуализировать результаты без необходимости писать сложный код. Однако, несмотря на растущую популярность и востребованность, no-code платформы по-прежнему сталкиваются с рядом серьезных вызовов, которые мешают им стать действительно универсальными и надежными инструментами для профессиональной работы с данными. Одной из основных сложностей является необходимость балансировать между простотой использования и гибкостью. Многие платформы проектируются так, чтобы быть максимально интуитивными для новичков, но слишком упрощенный интерфейс зачастую ограничивает возможности пользовательской кастомизации и настройки.
Это приводит к так называемому «стеклянному потолку», когда пользователи сталкиваются с ограничениями, которые вынуждают их либо переключаться на классическое программирование, либо отказаться от использования no-code решения вовсе. Поиск оптимального баланса между доступностью и функциональностью остается ключевой задачей разработчиков no-code продуктов. Еще одним критическим аспектом остается вопросы безопасности и конфиденциальности данных. Многие no-code платформы опираются на облачные сервисы, что диктует необходимость передачи чувствительной информации на удаленные серверы, что вызывает тревогу у организаций, работающих с медицинскими, финансовыми или государственными данными. В таких отраслях требования к соблюдению законов о защите персональной информации крайне жесткие, и облачные сервисы зачастую становятся неприменимыми из-за рисков утечек и несоответствий нормативам.
Поэтому в тренде появляются инструменты с офлайн-режимом работы или гибридными решениями, позволяющими локально обрабатывать данные без постоянного подключения к облаку, сохраняя высокие стандарты безопасности и соответствия законодательным требованиям. Образование пользователей и правильное применение no-code инструментов представляют собой отдельную сложную тему. Легкость использования таких платформ зачастую создает иллюзию простоты решения сложных задач, что может приводить к некорректному выбору алгоритмов, ошибкам в интерпретации результатов и, следовательно, к неправильным бизнес-решениям. Без должной подготовки и осознания принципов работы моделей, пользователи рискуют применять методы без понимания ограничений и допущений, заложенных в аналитические процессы. Многие современные платформы пытаются решить эту проблему с помощью встроенных встроенных AI-ассистентов, которые помогают пользователю в режиме реального времени понимать результаты, выбирать подходящие методы и предлагают рекомендации по корректировке моделей.
Тем не менее, вопрос интеграции целостных обучающих и контрольных систем в no-code продукты находится в стадии активного развития и требует дальнейшего совершенствования. Проблема закрытых экосистем также не теряет своей остроты. Некоторые платформы не предоставляют возможности экспортировать созданные модели и рабочие процессы в виде кода или документации, что затрудняет аудит, масштабирование и перенос проектов на другие инструменты. Закрытые интерфейсы создают зависимость от конкретных разработчиков и повышают риски технических долгов для компаний, стремящихся сохранять гибкость и прозрачность в управлении данными. Открытость, поддержка стандартизации и совместимость с открытыми форматами являются важным направлением развития no-code решений, способствующим их более широкому принятию в корпоративной среде.
Помимо технических и пользовательских проблем, no-code платформы должны постоянно адаптироваться под запросы рынка и интегрировать новые возможности искусственного интеллекта и автоматизации. В 2025 году все более востребованными становятся инструменты, способные поддерживать полный жизненный цикл анализа — от загрузки и очистки данных до построения, оценки и развертывания моделей, а также коллаборации внутри команд. Искусственный интеллект в этих системах перестает быть просто вспомогательным элементом, превращаясь в «партнера» пользователя, который не только выполняет команды, но и предлагает новые гипотезы, обнаруживает аномалии и формирует удобные отчетные материалы в виде понятных историй на языке домена бизнеса. Такой подход повышает эффективность совместной работы и помогает формировать более глубокое понимание данных без необходимости глубоких технических знаний. Важной характеристикой будущих no-code платформ станет возможность плавного перехода от визуальных конструкторов к редакторам кода.
Это позволит сочетать быстроту и простоту no-code с масштабируемостью и контролем кодовых решений, создавая гибридные среды, в которых аналитики смогут не только быстро создавать аналитику, но и дорабатывать результаты при необходимости. Общая тенденция к вертикализации no-code инструментов под конкретные отрасли с уникальными требованиями безопасности, соответствия и визуализации дополнительно усложняет задачу для разработчиков. Такие специализированные решения требуют не только универсальной гибкости, но и глубокого знания отраслевых норм, что требует серьезных вложений в разработку и поддержку. В целом, несмотря на существующие вызовы, no-code инструменты для data science продолжают стремительно развиваться, расширяя свои возможности и повышая уровень интеллекта и взаимодействия с пользователем. Их задача — не заменить разработчиков, а дать возможность более широкому кругу профессионалов работать с технически сложными задачами, упрощая процесс, но одновременно сохраняя прозрачность, безопасность и качество аналитики.
Интеграция машинного обучения, автоматизации, совместной работы и гибкости в одном продукте станет ключевым фактором успеха no-code проектов в ближайшем будущем, а развитие этих платформ проложит путь к более равноправному, эффективному и этичному использованию данных среди компаний и специалистов различных уровней.