В современном мире объем информации постоянно растет, и работа с электронными документами становится неотъемлемой частью повседневной деятельности как в бизнесе, так и в личных целях. Одним из самых популярных форматов хранения документов является PDF. Однако накопление большого количества PDF-файлов приводит к проблемам с их сортиировкой, поиском и структурированием. К счастью, инновационные решения на базе искусственного интеллекта сегодня позволяют автоматизировать процесс управления документами и существенно повысить продуктивность работы. Одним из таких современных решений является система категоризации PDF с использованием локальных языковых моделей, или LLM.
Эта технология сочетает в себе возможности глубокого обучения и естественной обработки языка для понимания содержания файлов и распределения их по тематическим категориям. В данной статье мы подробно рассмотрим, как работает такой инструмент, почему локальные LLM выгоднее облачных аналогов, и какие преимущества он приносит в повседневное использование. Изначально стоит отметить, что традиционные способы организации PDF, основанные на ручном переименовании файлов и создании папок, требуют значительного времени и усилий. К тому же, они ошибочны и часто приводят к ситуации, когда файл сложно найти даже обладателю. Современные языковые модели, способные распознавать контекст и тематику текста, позволяют существенно упростить этот процесс.
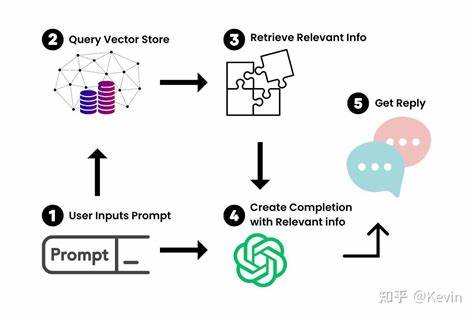
Идея состоит в том, что программа читает первую часть PDF-файла — заголовок и несколько первых страниц — извлекает текстовую информацию и анализирует ее с помощью встроенной языковой модели. В результате она выдает наиболее подходящую категорию, которая отражает содержание документа, после чего сам файл автоматически перемещается в соответствующую папку. Преимуществом использования локальных LLM является сохранение приватности данных. В отличие от облачных сервисов, где конфиденциальная информация отправляется на серверы третьих лиц, локальная установка модели позволяет всю обработку проводить на личном компьютере. Это критически важно для компаний, работающих с секретными документами, медицинскими данными, финансовой отчетностью и любой другой информацией, где утечка недопустима.
Реализация подобного инструмента базируется на нескольких ключевых компонентах. Во-первых, необходимо настроить локальную языковую модель в специализированном ПО, например LM Studio. Она должна работать в режиме, поддерживающем OpenAI-совместимый API, что облегчает интеграцию с пользовательскими скриптами. Во-вторых, важен корректный и гибкий конфигурационный файл, в котором указываются пути к директориям с PDF, количество страниц для анализа, название используемой модели, адрес API сервера и формат запроса к модели. Грамотно составленный запрос, называемый промптом, критически влияет на качество категоризации и позволяет адаптировать модель под конкретные задачи и тематику документов.
Функционально данное решение состоит из двух самостоятельных модулей. Первый — это категоризатор, который сканирует папку с файлами, извлекает из них текст, обращается к языковой модели с целью определения категории и сохраняет результаты в JSON-файл. Второй модуль — органайзер — читает эту JSON-базу и на основе классификации переносит PDF-файлы в соответствующие тематические папки. Такой подход не только структуирует коллекцию файлов, но и делает их поиск гораздо более интуитивным и быстрым. Помимо организации, использование локальной LLM предоставляет возможность масштабирования и индивидуальной доработки.
Можно подключить разные модели, экспериментировать с глубиной анализа, менять текстовые подсказки и получать максимально релевантные темы для разных типов документов — будь то техническая документация, научные статьи, договоры или обучающие материалы. Благодаря полному контролю над процессом, пользователь может без лишних ограничений улучшать качество классификации и подстраивать программу под собственные нужды. Кроме того, автоматизированный подход снижает ошибки, связанные с человеческим фактором, ускоряет время подготовки отчетов и систематизации материалов. В результате сотрудники компании получают удобный и надежный инструмент для управления огромным количеством документов, что положительно сказывается на продуктивности и общем уровне организации процессов. Важным аспектом является простота внедрения.
Для работы достаточно иметь установленные Python-библиотеки и запустить два простых скрипта — категоризатор и организатор. Благодаря тому, что все происходит локально, не требуется сложное серверное оборудование или дорогостоящее ПО. Это делает решение доступным для широкого круга пользователей, от индивидуальных специалистов до крупных предприятий. Среди перспектив дальнейшего развития можно выделить расширение возможностей модели с поддержкой многоязычности, интеграцию с другими инструментами документооборота и облачными хранилищами, а также использование усиленного машинного обучения для адаптации к специфике конкретной компании. Вне зависимости от области применения, локальные языковые модели уже сегодня демонстрируют огромный потенциал в сфере автоматизированной обработки и управления PDF-документами.
Подводя итог, стоит подчеркнуть, что PDF категоризация с помощью локальных LLM – это современное, надежное и конфиденциальное решение, позволяющее полностью изменить подход к работе с цифровыми документами. Эта технология не только упрощает повседневные задачи, но и служит фундаментом для построения эффективных систем управления информацией, которые будут востребованы в любых сферах деятельности. Внедрение таких инновационных инструментов открывает новые горизонты в автоматизации и значительно облегчает процессы хранения, поиска и анализа данных.