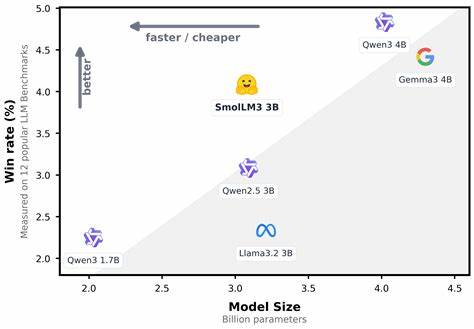
В быстроразвивающемся мире искусственного интеллекта небольшие языковые модели находят всё большее применение благодаря своей эффективности и удобству развертывания. Одним из ярких представителей такого подхода стала SmolLM3 — многоязычная модель с объёмом в 3 миллиарда параметров, способная обрабатывать контекст до 128 тысяч токенов и поддерживающая расширенные возможности рассуждения. Благодаря своей универсальности и производительности SmolLM3 занимает особое место среди современных решений, соперничая с более крупными системами, но при этом оставаясь значительно компактнее и экономичнее применительно к ресурсам. SmolLM3 основана на архитектуре трансформера с декодером, в основе которой лежит проверенная временем модель Llama, но с важными инновационными модификациями. Среди ключевых технических изменений — внедрение Grouped Query Attention (GQA), которая заменяет классическую многошаговую схему внимания, разделяя её на группы для оптимизации памяти и скорости вычислений.
Такая замена позволяет существенно уменьшить кэш ключей и значений на этапе инференса без потери качества генерации. Ещё одной важной новинкой стала реализация механизма NoPE — нового гибридного подхода к позиционному кодированию, который улучшает работу с длинным контекстом, исключая ротационные позиционные эмбеддинги (RoPE) на каждой четвертой слое. Такая тонкая оптимизация обеспечивает стабильную и эффективную обработку длинных последовательностей текста, увеличивая максимальную длину контекста до впечатляющих 128 тысяч токенов с помощью метода YaRN. Помимо архитектуры, в SmolLM3 большое внимание уделяется качеству данных и методам обучения. Модель была обучена на громадном объёме — 11 триллионов токенов, используя тщательно сбалансированную смесь базовых веб-данных, кода и математических задач.
Обучение проходило в несколько этапов с постепенным увеличением доли специализированных данных, направленных на развитие математических и программных навыков модели. Такое многоступенчатое обучение позволяет модели уверенно справляться с широким спектром задач в разных языках и областях знания. Одной из отличительных черт SmolLM3 является её многоязычность. Модель с одинаковой эффективностью работает не только на английском, но и на французском, испанском, немецком, итальянском и португальском языках. Это стало возможным благодаря расширенному словарю токенов, адаптированному для поддержки не только английского, но и других европейских языков — языкознание и кодирование были учтены разработчиками для улучшения компрессии и качества понимания.
Такой универсальный лингвистический охват особенно ценен для компаний и проектов, работающих на международном уровне. Особое внимание уделено не только базовой модели, но и её способностям к рассуждению и интерактивному взаимодействию. SmolLM3 поддерживает два режима работы — с включённым и выключенным режимом рассуждений (/think и /no_think), что позволяет пользователям выбирать между быстрой генерацией простых ответов и более глубоким, пошаговым анализом задачи. Это реализовано через специально разработанный чат-шаблон, дающий гибкость настройки и интеграции с инструментами. Модель также совместима с вызываемыми пользователем функциями и поддерживает работу с инструментами в форматах XML и Python, усиливая возможности применения в реальных сценариях.
Одной из инноваций в подготовке SmolLM3 стала этапная дообучающая фаза — mid-training. В этот период модель была дополнительно обучена на наборах данных, построенных специально для улучшения навыков работы с длинным контекстом и общей способности к рассуждению без привязки к конкретным предметным областям. Это позволило добиться значительных улучшений в сложных интеллектуальных задачах, таких как математические конкурсы, программирование и исследовательские викторины. Процесс обучения включал и этап дообучения под руководством учителя, который обеспечил сбалансированное развитие обеих режимов — рассуждений и простого инструкционного взаимодействия. Чтобы решить проблему нехватки данных с явными цепочками рассуждений, разработчики создали синтетические датасеты на основе выводов более крупных моделей, таких как Qwen3-32B.
Это дало возможность сохранять высокое качество и в сложных задачах, расширяя сферу применения SmolLM3. Для выравнивания модели и повышения качества результатов применён новый метод Anchored Preference Optimization (APO), разновидность Direct Preference Optimization. APO обеспечивает более стабильную и устойчивую оптимизацию предпочтений, сохраняя сопоставимость с исходной моделью и позволяя тонко настраивать её поведение в обоих режимах. В результате, SmolLM3 демонстрирует выдающиеся показатели на широком спектре тестов и бенчмарках, включая HellaSwag, ARC, GSM8K, MATH и многие другие, превосходя по ряду показателей конкурентов аналогичного размера. Нельзя не отметить впечатляющую производительность модели при работе с длинным контекстом, что далеко не тривиально для компактных моделей.
Благодаря постепенному увеличению размерности контекста от 4 тысяч до 64 тысяч во время обучения, а также использованию методов экстраполяции YaRN, SmolLM3 уверенно справляется с анализом больших документов, кода и иных структур данных, значительно расширяя возможности прикладного использования. Для разработчиков и исследователей SmolLM3 представляет собой не только высокотехнологичный инструмент, но и открытый проект, подробно документированный и доступный для изучения. Все рецепты обучения, архитектурные нюансы и подробные логи тренировок опубликованы на платформе Hugging Face и GitHub. Это создаёт уникальную возможность для сообщества воспроизводить и развивать идеи, ускоряя прогресс в области небольших, но мощных языковых моделей. Использование SmolLM3 очень удобно.
Модель интегрируется с популярными библиотеками, такими как transformers и vLLM, что облегчает запуск как на GPU, так и на CPU. Для обеспечения удобства пользователя реализованы простые интерфейсы для управления режимами рассуждений, в том числе возможность активации и деактивации расширенного мышления через простые системные сообщения. Поддержка инструментов вызова функции делает SmolLM3 отличным выбором для создания интеллектуальных агентов с доступом к внешним сервисам. В итоге SmolLM3 — это продвинутый и компактный языковой инструмент нового поколения, который объединяет в себе широкий языковой охват, длительный контекст и глубокие когнитивные способности. Он сочетает в себе лучшие достижения в области архитектурных решений, обучения на разнообразных данных и методик выравнивания, что позволяет решать задачи, которые ранее требовали больших и дорогих моделей.
Для исследователей, инженеров и разработчиков, работающих с ИИ, SmolLM3 открывает новые горизонты и возможности для реализации эффективных, масштабируемых и интеллектуальных решений.