В мире цифровой информации кодировки играют фундаментальную роль, позволяя компьютерам правильно обрабатывать и отображать текст на различных языках. Одним из наиболее значимых достижений в этой области стала кодировка UTF-8, получившая заслуженное признание благодаря своей простоте и универсальности. История UTF-8 - это история блестящей инженерной мысли и стремления обеспечить по-настоящему всемирное общение. В зародыше компьютерной эпохи, когда на смену телетайпам и механическим печатным устройствам приходили ЭВМ, программное сообщество стандартизировало только английский язык посредством кодировки ASCII. Этот набор из 128 символов достаточно полно покрывал латинский алфавит, цифры и несколько специальных знаков.
Однако для поддержки всех других языков мира, включая европейские с диакритическими знаками, азиатские и многие другие, ASCII оказался крайне ограничен. Появилась острая необходимость в расширенной кодировке, способной передавать многообразие человеческих символов и знаков. Ранее существовали различные попытки расширить ASCII, например, с использованием фиксированной ширины двух байт, но они сталкивались с рядом проблем - от неэффективности использования места в памяти до сложности обработки и несовместимости с уже существующими текстами. Именно в данной среде и родилась идея UTF-8, предложенная известными учёными и инженерами - Кеном Томпсоном и Робом Пайком. Их предложение в 1992 году стало настоящим "взрывом" в мире кодировок.
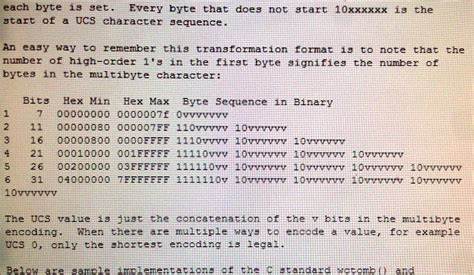
UTF-8 представляет собой многобайтовую кодировку, которая умеет кодировать любой символ универсального стандарта Unicode. Одной из ключевых особенностей UTF-8 стала обратная совместимость с ASCII, что означало, что все символы ASCII кодируются в один байт и при этом имеют идентичное представление как в UTF-8. Это позволило программам и системам легко интегрировать новую кодировку без радикальных изменений. Выделяет UTF-8 и способ обозначения многобайтовых последовательностей символов. Каждый байт в последовательности имеет уникальную структуру разметки битов, позволяющую однозначно определить начало и продолжение символа.
Это обеспечивает "самосинхронизацию" - возможность обработать данные, начав разбор с любой точки текста, что критично для устойчивости работы в условиях возможных ошибок и повреждений данных. Самой впечатляющей чертой UTF-8 является её элегантность и простота. Использование механизма с изменяющейся длиной кодовой единицы от одного до четырёх байт позволяет эффективно экономить память при работе с обычным текстом на английском и других распространённых языках, в то время как в случае редких и сложных символов используется больше байт. Такая универсальная модель умело сбалансировала эффективность хранения и охват всего спектра возможных символов. Большое достоинство UTF-8 - его универсальность и широкая поддержка.
Сегодня практически все популярные операционные системы, программные платформы и веб-приложения по умолчанию используют UTF-8, что превратило её в фактический стандарт интернета и цифровых коммуникаций. Библиотеки и языки программирования интегрировали поддержку UTF-8, что существенно упростило разработку по всему миру, сняло барьеры для локализации и многоязычного взаимодействия. Несмотря на блестящие технические решения, на пути внедрения UTF-8 встречались и сложности. Например, представители крупных компаний настаивали на добавлении так называемого Byte Order Mark (BOM) - специальной метки в начале файла, чтобы упростить определение кодировки. Однако это нарушало одно из важнейших достоинств UTF-8 - совместимость с ASCII, поскольку приведённый спецсимвол мог восприниматься как часть данных.
Тем не менее, сообщество разработчиков сумело выработать лучшие практики и обходные решения. Изучение истории UTF-8, особенно в контексте первоначального письма Кена Томпсона, где он впервые описал идею [документ широко доступен и изучается программистами и историками технологий], дает потрясающий урок инженерной мысли. Простота и логичность продуманного подхода поражают: несмотря на первичное похожее на "хак" решение, грамотное использование битовых масок и логики позволило создать эффективный и универсальный стандарт. Такая "элегантность хака" стала вдохновением для многих в мире IT. Нельзя не отметить и влияние UTF-8 на развитие глобальной культуры и коммуникаций.
До её появления поддержка множества разных языков была сложной задачей, ограниченной платформами и программами. Сегодня люди свободно обмениваются данными на родных языках с минимальными техническими проблемами. Unicode и UTF-8 - это технология, которая фактически стирает границы. При всём своем совершенстве UTF-8 требует от разработчиков понимания особенностей работы с многоязычными данными, особенно при обработке символов на уровне байтов, работы с длинами строк и нормализацией. В языке Python, например, долгое время Unicode обрабатывался не без сложностей, а переход к полноценной поддержке UTF-8 связан с переосмыслением архитектуры и борьбы с наследием предыдущих версий.
Тем не менее, благодаря усилиям глобального сообщества, программирование с использованием UTF-8 становится всё более привычным и удобным. Также стоит вспомнить, что UTF-8 стала не просто стандартом техническим, но и примером международного сотрудничества и понимания важности единого подхода для развития современных технологий. Примеры алгоритмической эффективности и продуманности работы с данными из истории ASCII, хранящие память о сложностях ранних ЭВМ, плавно перетекают в универсальное решение, которое легко масштабируется и адаптируется. Подводя итог, UTF-8 - это блестящий пример того, как простая, хорошо продуманная инженерия может кардинально изменить ландшафт цифрового мира. От механических печатных устройств до смартфонов и веб-сайтов - UTF-8 стала неотъемлемой частью повседневной жизни миллионов людей, поддерживая многообразие языков и культур.
Современным программистам полезно не только знать об этом стандарте, но и понимать его глубинную суть, черпать вдохновение из истории его создания и стремиться к таким же элегантным решениям в собственных проектах. .

![The Prisoner of Beauty ปรปักษ์จำนน พากย์ไทย ซับไทย Ep1-Ep36 [จบ]](/images/B519D2C8-7FD6-4997-A6D1-504BBECC509D)
![[ตัวอย่างพากย์ไทย] ปรปักษ์จำนน The Prisoner of Beauty 2025 ออนแอร์ 3](/images/3635B27C-6540-44AA-9E5E-30892BB957FB)



