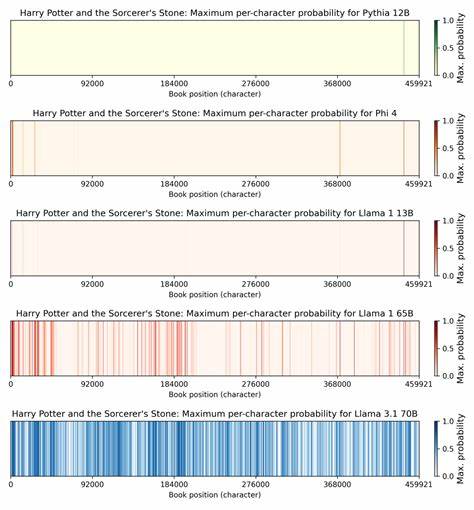
За последние два десятилетия дата-инжиниринг прошел глубокую трансформацию, превратившись из узкоспециализированной роли поддержки баз данных в полноценное направление с высокотехнологичной экосистемой. Современный дата-инженер — это профессионал широкого профиля, который совмещает в себе знания системного администрирования, программирования, DevOps и работы с большими данными. Чтобы успешно конкурировать на рынке и создавать надежные, масштабируемые решения, требуется владение большим набором инструментов и технологий, которые эволюционировали вместе с отраслью. В центре внимания находится «Набор инструментов дата-инженера», в котором собраны ключевые компоненты, обобщающие опыт более чем двадцатилетней практики в сфере обработки данных. Этот набор формирует своеобразную «платформу» для самостоятельного построения эффективных и гибких систем, позволяющих справляться с возросшими требованиями к скорости, качеству и управляемости данных.
Ключевым фундаментом любого дата-инженера остаются системные знания. Владение Linux и командной строкой — это необходимый минимум. Работа с WSL (подсистема Windows для Linux), curl, rsync и другими утилитами позволяет управлять и автоматизировать обмен данными, проверять целостность и эффективно взаимодействовать с удалёнными системами. Инструменты поиска и фильтрации, такие как ripgrep, fzf и bat, значительно ускоряют анализ и обработку логов, скриптов и результатов запросов. Это не просто рутинные навыки, а базис при создании надёжных и повторяемых процессов.
Для разработки и поддержки своих решений современные дата-инженеры используют мощные IDE и облачные среды разработки. VS Code, Jupyter Notebooks, а также продвинутые инструменты AI IDEs и GitHub Codespaces становятся обязательной частью рабочего процесса. Способность быстро адаптироваться к новым средам, писать чистый, тестируемый код на Python, Scala или других языках, а также использовать Git для контроля версий — ключ к успеху при командной работе и масштабировании проектов. SQL остается основным языком работы с данными. Технологии PostgreSQL, DuckDB и интеграция с Polars и Pandas предоставляют гибкие возможности для манипуляций с таблицами и аналитики.
Современные движки запросов, такие как Spark SQL, значительно расширяют возможности обработки больших данных в распределенных системах. Понимание принципов работы реляционных баз данных дополняется навыками моделирования данных и построения эффективных ETL/ELT-процессов. Важно не только уметь получить и преобразовать данные, но и контролировать их качество, проводить валидацию и соблюдать жизненный цикл данных от сбора до архивирования. Современный дата-инжиниринг невозможно представить без облачных технологий и инструментов оркестрации. Kubernetes и Docker стали стандартом в деплойменте и управлении контейнерами, позволяя изолировать сервисы, обеспечивая удобство масштабирования, восстановления и обновления.
Инструменты Terraform, Helm и Kustomize облегчает управление инфраструктурой как кодом, что дает возможность автоматизировать развёртывание сложных систем и повышать их надежность. В концепции GitOps DevOps-подходы органично интегрируются с задачами для данных, позволяя выстраивать процессы, где инфраструктура и код существуют в едином источнике истины. Важной составляющей являются продвинутые инструменты для обработки и хранения данных. Объекты хранилищ, такие как MinIO и S3, обеспечивают надежное хранение больших объемов данных в стандартизированном формате Parquet, что значительно повышает скорость чтения и обработки. Использование терминалов tmux, плагинов для Vim и вспомогательных инструментов вроде lazypocker и k9s формируют комфортную среду управления и мониторинга систем.
Открытые форматы таблиц и каталоги данных помогают систематизировать информацию и обеспечивают масштабируемость архитектуры. С развитием искусственного интеллекта появились новые возможности интеграции AI в рабочие процессы дата-инженера. Инструменты, такие как GitHub Copilot, значительно ускоряют написание кода благодаря автодополнению и подсказкам. Vector databases и embeddings позволяют хранить и индексиовать сложные данные для применения в поисковых системах с использованием семантики. Модели извлечения знаний (RAG) и протоколы передачи контекста становятся удобными инструментами для реализации интеллектуальных систем, автоматизирующих принятие решений и работу с неструктурированной информацией.
Особое внимание уделяется качеству и наблюдаемости данных. Использование систем тестирования, таких как Great Expectations и Pandera, помогает гарантировать корректность и консистентность данных в различных этапах обработки и передачи. Реализация подходов OpenLineage и Data Contracts увеличивает прозрачность, позволяя быстро выявлять и исправлять нарушения в потоках данных, обеспечивая их соответствие бизнес-правилам и стандартам. Управление схемами, отслеживание их эволюции и предотвращение дрейфа — важные процессы для стабильной работы аналитических и операционных систем. Опыт, накопленный за последние 20 лет, показывает, что эффективный дата-инженер — это не просто специалист по конкретному инструменту, а стратег, владеющий технологическим стеком целиком.
Он понимает важность выстраивания комплексной архитектуры, где каждый компонент работает в связке с другими, обеспечивая гибкость, безопасность и масштабируемость всех процессов. Текущая практика свидетельствует, что переход к DevOps-культуре является ключевым фактором успеха, позволяя перевести задачи дата-инжиниринга в плоскость автоматизации и кодирования. Кроме того, расширение компетенций в области моделирования данных и анализа бизнес-требований позволяет создавать решения, максимально заточенные под конкретные задачи компании. Это помогает не только снизить затраты на поддержку инфраструктуры, но и повысить качество принимаемых решений за счет достоверных и вовремя предоставленных данных. Для тех, кто стремится к глубокому пониманию и быстрому развитию в этой области, существует «Хранилище знаний по дата-инжинирингу» — обширная база данных с интерактивными графами, связями между терминами и понятиями, а также подробной информацией по актуальным технологиям и методологиям.